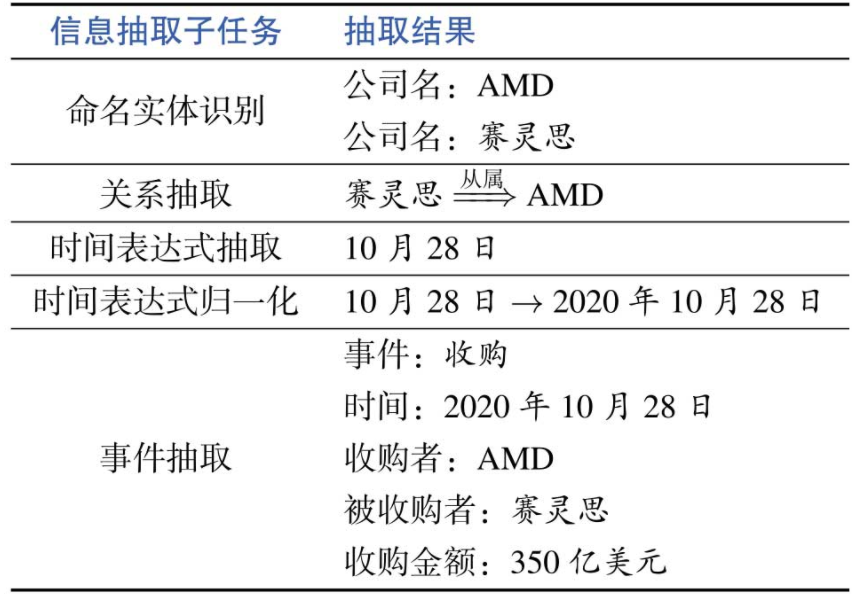
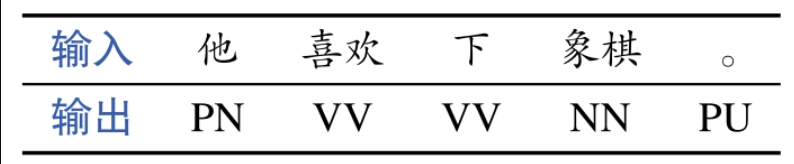
《自然语言处理基于预训练模型的方法》- 第4章静态词向量预训练模型「学习笔记」
简单的词向量预训练
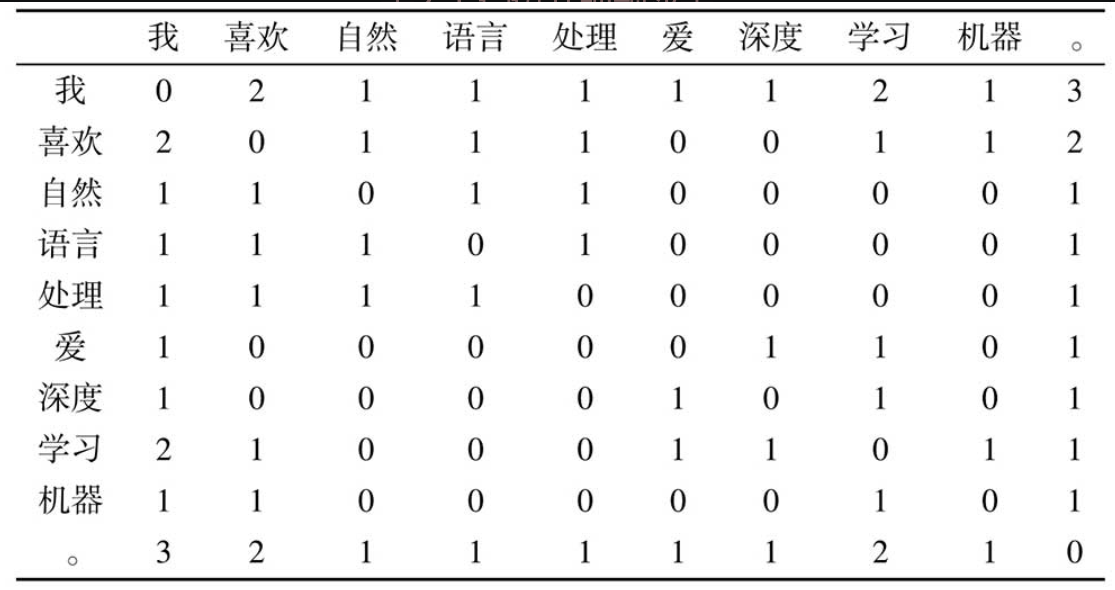
预训练任务
- 基本任务就是根据上下文预测下一时刻词: $P\left(w_{t} \mid w_{1} w_{2} \ldots w_{t-1}\right) $
- 这种监督信号来自于数据自身,因此称为 自监督学习 。
前馈神经网络预训练词向量
- 输入层→词向量层→隐含层→输出层
- 训练后,词向量矩阵$ \boldsymbol{E} \in \mathbb{R}^{d \times|\mathbb{V}|}$即为预训练得到的静态词向量。
class NGramDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
# context_size:上下文大小为2
self.data = []
self.bos = vocab[BOS_TOKEN] # 句首标记id
self.eos = vocab[EOS_TOKEN] # 句尾标记id
for sentence in tqdm(corpus, desc="Dataset Construction"):
# 插入句首、句尾标记符
sentence = [self.bos] + sentence + [self.eos]
# 如句子长度小于预定义的上下文大小,则跳过
if len(sentence) < context_size:
continue
for i in range(context_size, len(sentence)):
# 模型输入:长为context_size的上文
context = sentence[i-context_size:i]
# 模型输出:当前词
target = sentence[i]
# 每个训练样本由(context,target)构成
self.data.append((context, target))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
# 从独立样本集合中构建batch的输入输出,并转换为PyTorch张量类型
inputs = torch.tensor([ex[0] for ex in examples], dtype=torch.long)
targets = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
return (inputs, targets)
class FeedForwardNNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, context_size, hidden_dim):
super(FeedForwardNNLM, self).__init__()
# 词嵌入层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 线性变换:词嵌入层->隐含层
self.linear1 = nn.Linear(context_size * embedding_dim, hidden_dim)
# 线性变换:隐含层->输出层
self.linear2 = nn.Linear(hidden_dim, vocab_size)
# 使用ReLU激活函数
self.activate = F.relu
init_weights(self)
def forward(self, inputs):
embeds = self.embeddings(inputs).view((inputs.shape[0], -1))
hidden = self.activate(self.linear1(embeds))
output = self.linear2(hidden)
# 根据输出层(logits)计算概率分布并取对数,以便于计算对数似然
# 这里采用PyTorch库的log_softmax实现
log_probs = F.log_softmax(output, dim=1)
return log_probs
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
# 读取文本数据,构建FFNNLM训练数据集(n-grams)
corpus, vocab = load_reuters()
# print(corpus[0])
# print(corpus.shape)
dataset = NGramDataset(corpus, vocab, context_size)
data_loader = get_loader(dataset, batch_size)
# 负对数似然损失函数
nll_loss = nn.NLLLoss()
# 构建FFNNLM,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = FeedForwardNNLM(len(vocab), embedding_dim, context_size, hidden_dim)
model.to(device)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
total_losses = []
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
inputs, targets = [x.to(device) for x in batch]
optimizer.zero_grad()
log_probs = model(inputs)
loss = nll_loss(log_probs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
total_losses.append(total_loss)
# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "ffnnlm.vec")模型在训练集上的损失随着迭代轮次的增加而不断减小。需要注意的是,由于训练的目标是获取词向量而不是语言模型本身,所以在以上训练过程中,并不需要以模型达到收敛状态(损失停止下降)作为训练终止条件。
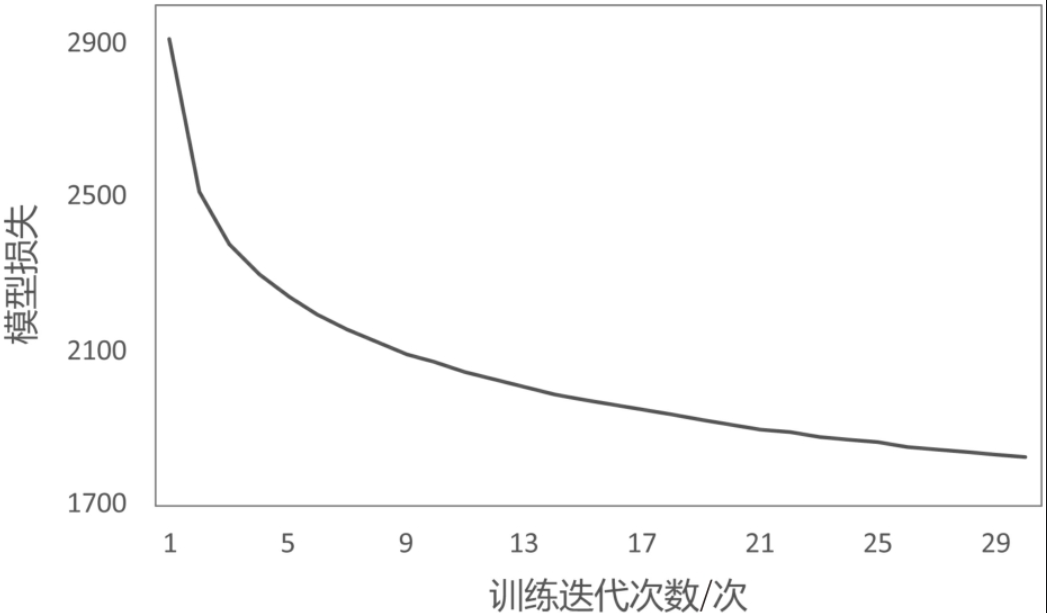
训练过程中模型损失的变化曲线
循环神经网络预训练词向量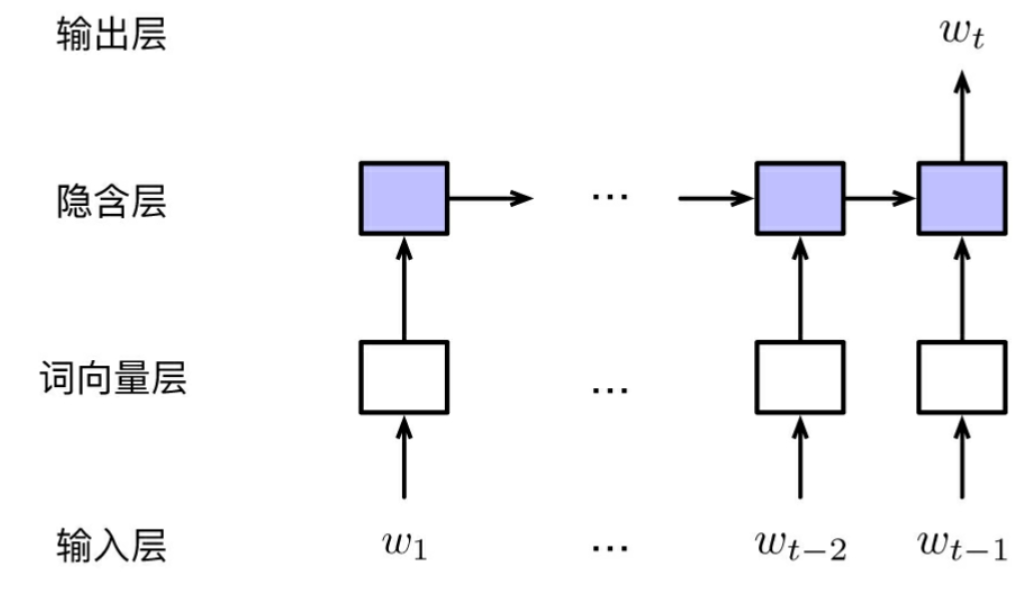
创建数据类RnnlmDataset
RnnlmDataset实现训练数据的构建和存取。
对于句子w1w2··· wn,循环神经网络的输入序列为<bos>w1w2··· wn1w2··· wn,输出序列为w1w2··· wn<eos>。与基于定长上下文的前馈神经网络语言模型不同,RNNLM的输入序列长度是动态变化的,因此在 构建批次时,需要对批次内样本进行补齐 ,使其长度一致。
class RnnlmDataset(Dataset):
def __init__(self, corpus, vocab):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
self.pad = vocab[PAD_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
# 模型输入:BOS_TOKEN, w_1, w_2, ..., w_n
input = [self.bos] + sentence
# 模型输出:w_1, w_2, ..., w_n, EOS_TOKEN
target = sentence + [self.eos]
self.data.append((input, target))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
# 从独立样本集合中构建batch输入输出
inputs = [torch.tensor(ex[0]) for ex in examples]
targets = [torch.tensor(ex[1]) for ex in examples]
# 对batch内的样本进行padding,使其具有相同长度
inputs = pad_sequence(inputs, batch_first=True, padding_value=self.pad)
targets = pad_sequence(targets, batch_first=True, padding_value=self.pad)
return (inputs, targets)模型:选用LSTM
- 输入层→词向量层→隐含层→输出层
class RNNLM(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim):
super(RNNLM, self).__init__()
# 词嵌入层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 循环神经网络:这里使用LSTM
self.rnn = nn.LSTM(embedding_dim, hidden_dim, batch_first=True)
# 输出层
self.output = nn.Linear(hidden_dim, vocab_size)
def forward(self, inputs):
embeds = self.embeddings(inputs)
# 计算每一时刻的隐含层表示
hidden, _ = self.rnn(embeds)
output = self.output(hidden)
log_probs = F.log_softmax(output, dim=2)
return log_probs训练
训练过程与前馈神经网络基本一致,由于输入输出序列可能较长,因此可以视情况调整批次大小(batchsize)。
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
# 读取文本数据,构建FFNNLM训练数据集(n-grams)
corpus, vocab = load_reuters()
dataset = RnnlmDataset(corpus, vocab)
data_loader = get_loader(dataset, batch_size)
# 负对数似然损失函数,忽略pad_token处的损失
nll_loss = nn.NLLLoss(ignore_index=dataset.pad)
# 构建RNNLM,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = RNNLM(len(vocab), embedding_dim, hidden_dim)
model.to(device)
# 使用Adam优化器
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
inputs, targets = [x.to(device) for x in batch]
optimizer.zero_grad()
log_probs = model(inputs)
loss = nll_loss(log_probs.view(-1, log_probs.shape[-1]), targets.view(-1))
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
save_pretrained(vocab, model.embeddings.weight.data, "rnnlm.vec")- 然后把词向量层参数和词表(一一对应)保存下来就是静态词向量
Word2Vec 词向量
由于之前的神经网络预训练词向量方法存在一个缺陷,就是当对t时刻词进行预测时,模型只利用了历史词序列作为输入,从而损失了与“未来”上下文之间的共现信息,因此引入Word2wec。
CBOW模型
给定一段文本,CBOW模型的基本思想是根据上下文对目标词进行预测。
对于$w_{t-2} w_{t-1}\quad w_{t} w_{t+1} w_{t+2}$,CBOW模型的任务是根据一定窗口大小内的上下文Ct(若取窗口大小为5,则Ct={wt−2, wt−1, wt+1, wt+2})对t时刻的词wt进行预测。与神经网络语言模型不同。
特点
CBOW模型不考虑上下文中单词的位置或者顺序,因此模型的输入实际上是一个“词袋”而非序列,这也是模型取名为“Continuous Bag-of-Words”的原因。
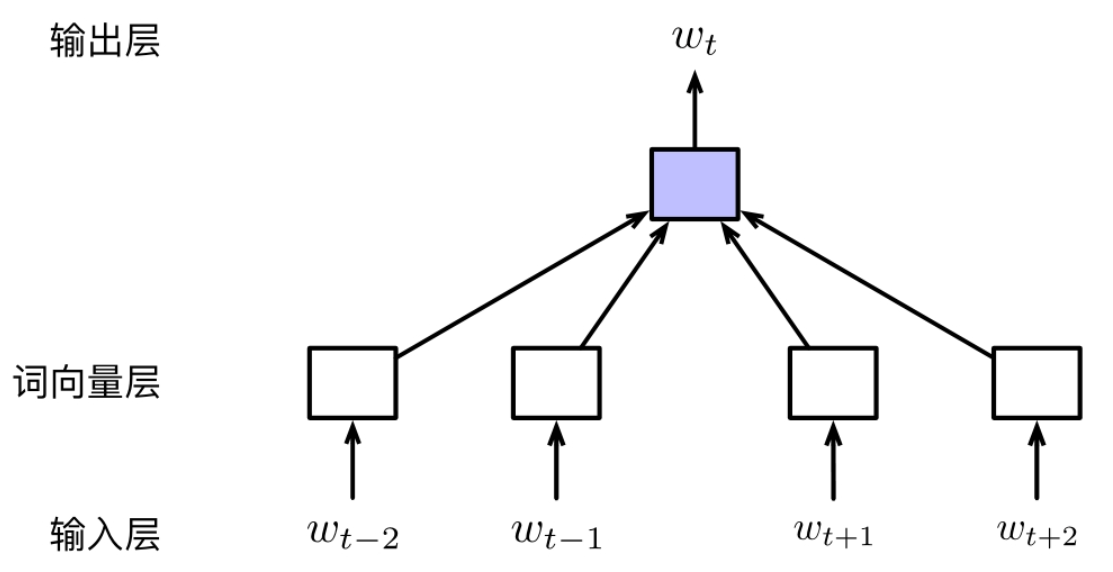
CBOW模型为上图所示的前馈神经网络结构。与一般的前馈神经网络相比,CBOW模型的隐含层只是执行对词向量层取平均的操作,而没有线性变换以及非线性激活的过程。所以,也可以认为CBOW模型是没有隐含层的,这也是CBOW模型具有高训练效率的主要原因。
输入层
**以大小为5的上下文窗口为例,在目标词的左右各取2个词作为模型输入。输入层由4个维度为词表长度|V|的独热表示向量构成。$e_{w_{i}}=[0 ; \ldots ; 1 ; \ldots 0] \in[[0,1]]^{\mathbb{V}_{\perp}}$
词向量层
输入层的每个词的独热表示经由局长$\pmb{E}\in\mathbb{R}^{d\times|\mathbb{V}|}$映射至词向量空间。\boldsymbol{v}_{w_{i}}=\boldsymbol{E} \boldsymbol{e}_{w_{i}}
Wi对应的词向量即为矩阵E中相应位置的列向量,E则为由所有词向量构成的矩阵或查找表。令Ct={Wt−k,···, Wt−1, Wt+1,···, Wt+k}表示Wt的上下文单词集合, 对Ct中所有词向量取平均操作 ,就得到了Wt的上下文表示:
$$ \boldsymbol{v}_{\mathcal{C}_{t}}=\frac{1}{\left|\mathcal{C}_{t}\right|} \sum_{w \in \mathcal{C}_{t}} \boldsymbol{v}_{w} $$
输出层
输出层参数 $\boldsymbol{E}^{\prime} \in \mathbb{R}^{\mathbb{V} \mid \times d}$
$$ P\left(w_{t} \mid \mathcal{C}_{t}\right)=\frac{\exp \left(\boldsymbol{v}_{\mathcal{C}_{t}} \cdot \boldsymbol{v}_{w_{t}}^{\prime}\right)}{\sum_{w^{\prime} \in \mathbb{V}} \exp \left(\boldsymbol{v}_{\mathcal{C}_{t}} \cdot \boldsymbol{v}_{w^{\prime}}^{\prime}\right)} $$
$v_{w_{i}}^{\prime}$是$E^{\prime}$与对应$w_{i}$的行向量。
词向量矩阵
$E和{E}^{\prime}$都可以作为词向量矩阵,他们分别表示了词在作为条件上下文或目标词时的不同性质。常用$E$也可以两者组合起来。
创建数据类CbowDataset
class CbowDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence+ [self.eos]
if len(sentence) < context_size * 2 + 1:
continue
for i in range(context_size, len(sentence) - context_size):
# 模型输入:左右分别取context_size长度的上下文
context = sentence[i-context_size:i] + sentence[i+1:i+context_size+1]
# 模型输出:当前词
target = sentence[i]
self.data.append((context, target))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
inputs = torch.tensor([ex[0] for ex in examples])
targets = torch.tensor([ex[1] for ex in examples])
return (inputs, targets)模型:CBOW
class CbowModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(CbowModel, self).__init__()
# 词嵌入层
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
# 线性变换:隐含层->输出层
self.output = nn.Linear(embedding_dim, vocab_size)
init_weights(self)
def forward(self, inputs):
embeds = self.embeddings(inputs)
# 计算隐含层:对上下文词向量求平均
hidden = embeds.mean(dim=1)
output = self.output(hidden)
log_probs = F.log_softmax(output, dim=1)
return log_probs训练
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
# 读取文本数据,构建CBOW模型训练数据集
corpus, vocab = load_reuters()
dataset = CbowDataset(corpus, vocab, context_size=context_size)
data_loader = get_loader(dataset, batch_size)
nll_loss = nn.NLLLoss()
# 构建CBOW模型,并加载至device
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = CbowModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
inputs, targets = [x.to(device) for x in batch]
optimizer.zero_grad()
log_probs = model(inputs)
loss = nll_loss(log_probs, targets)
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
# 保存词向量(model.embeddings)
save_pretrained(vocab, model.embeddings.weight.data, "cbow.vec")skip-gram模型
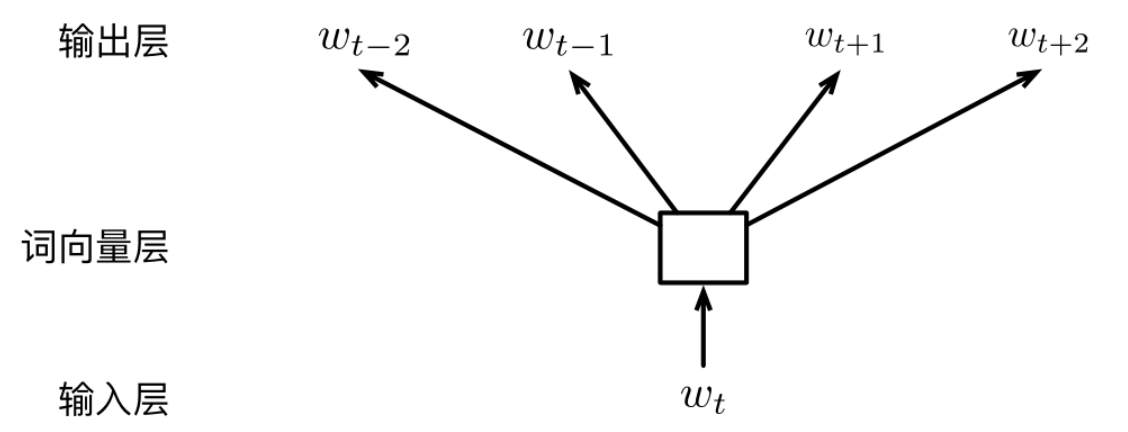
**使用 Ct 中的每个词作为独立的上下文对目标词进行预测”, 即 $P\left(w_{t} \mid w_{t+j}\right)$
**原文献是$P\left(w_{t+j} \mid w_{t}\right)$两者等价
- 隐藏层向量:$v_{w_{t}}=\boldsymbol{E}_{w_{t}}^{T}$
- 输出层:参数为 $\boldsymbol{E}^{\prime} \in \mathbb{R}^{\mathbb{V} \times d}, P\left(c \mid w_{t}\right)=\frac{\exp \left(v_{w_{t}} \cdot v_{c}^{\prime}\right)}{\sum_{w^{\prime} \in \mathbb{V}} \exp \left(v_{w_{t}} \cdot v_{w^{\prime}}^{\prime}\right)}$
- 其中$v_{w_{i}}^{\prime}$是$E^{\prime}$与对应$w_{i}$的行向量。
- 词向量层:与CBOW相同
skip-gram Dataset
class SkipGramDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence)-1):
# 模型输入:当前词
w = sentence[i]
# 模型输出:一定上下文窗口大小内共现的词对
left_context_index = max(0, i - context_size)
right_context_index = min(len(sentence), i + context_size)
context = sentence[left_context_index:i] + sentence[i+1:right_context_index+1]
self.data.extend([(w, c) for c in context])
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
inputs = torch.tensor([ex[0] for ex in examples])
targets = torch.tensor([ex[1] for ex in examples])
return (inputs, targets)模型-skip-gram
class SkipGramModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SkipGramModel, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embedding_dim)
self.output = nn.Linear(embedding_dim, vocab_size)
init_weights(self)
def forward(self, inputs):
embeds = self.embeddings(inputs)
output = self.output(embeds)
log_probs = F.log_softmax(output, dim=1)
return log_probs参数估计与预训练任务
- 需要估计的参数:$\boldsymbol{\theta}=\left\{\boldsymbol{E}, \boldsymbol{E}^{\prime}\right\}$
CBOW模型的负对数似然损失函数为:
$$ \mathcal{L}(\boldsymbol{\theta})=-\sum_{t=1}^{T} \log P\left(w_{t} \mid \mathcal{C}_{t}\right) $$
Skip-gram模型的负对数似然损失函数为:
$$ \mathcal{L}(\boldsymbol{\theta})=-\sum_{t=1}^{T} \sum_{-k \leq j \leq k, j \neq 0} \log P\left(w_{t+j} \mid w_{t}\right)$ $$
负采样
- 输出层的归一化计算效率低(当词表很大的时候)
- 样本 $(w,c)$正样本$c = W{t + j}$,对c进行若干次负采样得到:$\tilde{w}_{i}(i=1, \ldots, K)$
- 给定当前词 w ww 与上下文词 c cc ,最大化两者共现概率;即简化为对于
 的二元分类问题
的二元分类问题 - 共现:$P(D=1 \mid w, c)=\sigma\left(\boldsymbol{v}_{w} \cdot \boldsymbol{v}_{c}^{\prime}\right)$
- 不共现:
- 对数似然
 改为
改为

,其中 。
。
- 负采样分布的选择:假设
 表示从训练语料中统计得到的 Unigram 分布,目前通常会使用实际效果较好的负采样分布,如下:
表示从训练语料中统计得到的 Unigram 分布,目前通常会使用实际效果较好的负采样分布,如下:
负样本采样实现-skipgram
Skip-gram负采样Dataset
class SGNSDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2, n_negatives=5, ns_dist=None):
self.data = []
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
self.pad = vocab[PAD_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence)-1):
# 模型输入:(w, context) ;输出为0/1,表示context是否为负样本
w = sentence[i]
left_context_index = max(0, i - context_size)
right_context_index = min(len(sentence), i + context_size)
context = sentence[left_context_index:i] + sentence[i+1:right_context_index+1]
context += [self.pad] * (2 * context_size - len(context))
self.data.append((w, context))
# 负样本数量
self.n_negatives = n_negatives
# 负采样分布:若参数ns_dist为None,则使用uniform分布
self.ns_dist = ns_dist if ns_dist is not None else torch.ones(len(vocab))
def __len__(self):
return len(self.data)
def __getitem__(self, i):
return self.data[i]
def collate_fn(self, examples):
words = torch.tensor([ex[0] for ex in examples], dtype=torch.long)
contexts = torch.tensor([ex[1] for ex in examples], dtype=torch.long)
batch_size, context_size = contexts.shape
neg_contexts = []
# 对batch内的样本分别进行负采样
for i in range(batch_size):
# 保证负样本不包含当前样本中的context
ns_dist = self.ns_dist.index_fill(0, contexts[i], .0)
# 进行取样,multinomial 是均匀的,反正就是一定根据 ns_dist 取样
neg_contexts.append(torch.multinomial(ns_dist, self.n_negatives * context_size, replacement=True))
neg_contexts = torch.stack(neg_contexts, dim=0)
return words, contexts, neg_contexts对于每个训练(正)样本,需要根据某个负采样概率分布生成相应的负样本,同时需要保证负样本不包含当前上下文窗口内的词。这次采用的实现方式是,在构建训练数据的过程中就完成负样本的生成,这样在训练时直接读取负样本即可。这样做的优点是训练过程无须再进行负采样,因而效率较高;缺点是每次迭代使用的是同样的负样本,缺乏多样性。
模型
其中需要维护两个词向量: 和
和  各维护一个 w_embedding 和 c_embedding , 然后 各设置一个 forward_w 和 forward_c, 然后将词向量矩阵和上下文向量矩阵合并作为最终的词向量矩阵,
各维护一个 w_embedding 和 c_embedding , 然后 各设置一个 forward_w 和 forward_c, 然后将词向量矩阵和上下文向量矩阵合并作为最终的词向量矩阵,
<span class="ne-text">combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight </span>之所以这么做,是因为每个词向量要包含该词作为目标词和作为上下文的两者的信息。
因为每个词向量要包含该词作为目标词和作为上下文的两者的信息
class SGNSModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(SGNSModel, self).__init__()
# 词嵌入
self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)
# 上下文嵌入
self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)
def forward_w(self, words):
w_embeds = self.w_embeddings(words)
return w_embeds
def forward_c(self, contexts):
c_embeds = self.c_embeddings(contexts)
return c_embeds
训练
def get_unigram_distribution(corpus, vocab_size):
# 从给定语料中统计unigram概率分布
token_counts = torch.tensor([0] * vocab_size)
total_count = 0
for sentence in corpus:
total_count += len(sentence)
for token in sentence:
token_counts[token] += 1
unigram_dist = torch.div(token_counts.float(), total_count)
return unigram_dist
embedding_dim = 64
context_size = 2
hidden_dim = 128
batch_size = 1024
num_epoch = 10
n_negatives = 10 # 负采样样本的数量
# 读取文本数据
corpus, vocab = load_reuters()
# 计算unigram概率分布
unigram_dist = get_unigram_distribution(corpus, len(vocab))
# 根据unigram分布计算负采样分布: p(w)**0.75
negative_sampling_dist = unigram_dist ** 0.75
negative_sampling_dist /= negative_sampling_dist.sum()
# 构建SGNS训练数据集
dataset = SGNSDataset(
corpus,
vocab,
context_size=context_size,
n_negatives=n_negatives,
ns_dist=negative_sampling_dist
)
data_loader = get_loader(dataset, batch_size)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = SGNSModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
words, contexts, neg_contexts = [x.to(device) for x in batch]
optimizer.zero_grad()
batch_size = words.shape[0]
# 提取batch内词、上下文以及负样本的向量表示
word_embeds = model.forward_w(words).unsqueeze(dim=2)
context_embeds = model.forward_c(contexts)
neg_context_embeds = model.forward_c(neg_contexts)
# 正样本的分类(对数)似然
context_loss = F.logsigmoid(torch.bmm(context_embeds, word_embeds).squeeze(dim=2))
context_loss = context_loss.mean(dim=1)
# 负样本的分类(对数)似然
neg_context_loss = F.logsigmoid(torch.bmm(neg_context_embeds, word_embeds).squeeze(dim=2).neg())
neg_context_loss = neg_context_loss.view(batch_size, -1, n_negatives).sum(dim=2)
neg_context_loss = neg_context_loss.mean(dim=1)
# 损失:负对数似然
loss = -(context_loss + neg_context_loss).mean()
loss.backward()
optimizer.step()
total_loss += loss.item()
print(f"Loss: {total_loss:.2f}")
# 合并词嵌入矩阵与上下文嵌入矩阵,作为最终的预训练词向量
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "sgns.vec")Glove词向量
传统的词向量预训练本质上都是利用文本中词与词在局部上下文中的共现信息作为自监督学习信号,另一种是通过矩阵分解的方法,如SVD分解。
GloVe模型的基本思想是利用词向量对“词--上下文”共现矩阵进行预测(或者回归),从而实现隐式的矩阵分解。
- 构建贡献矩阵
 ,但是限制在受限窗口大小内得贡献次数(即要使w和c的距离要足够小)
,但是限制在受限窗口大小内得贡献次数(即要使w和c的距离要足够小) - 当w与c共现时,w与c之间的距离
 ,Glove认为距较远的全共效次的贡献数较小
,Glove认为距较远的全共效次的贡献数较小 - 在获得矩阵M之后,利用词与上下文向量表示对M中的元素(取对数)进行回归计算。具体形式为

 分别是w和c的向量表示(就是他们的Glove词向量),
分别是w和c的向量表示(就是他们的Glove词向量), 分别是相应的偏置项。
分别是相应的偏置项。
参数估计


式中, 表示每一个
表示每一个 样本的权重,与共现次数有关。GloVe采用了以下的分段函数进行加权:
样本的权重,与共现次数有关。GloVe采用了以下的分段函数进行加权:

当 不超过某个阈值max时,的值单调递增且小于等于1,他的增长速率由α控制;当超过某个阈值max时,的值恒等于1.
不超过某个阈值max时,的值单调递增且小于等于1,他的增长速率由α控制;当超过某个阈值max时,的值恒等于1.
Glove Dataset
class GloveDataset(Dataset):
def __init__(self, corpus, vocab, context_size=2):
# 记录词与上下文在给定语料中的共现次数
self.cooccur_counts = defaultdict(float)
self.bos = vocab[BOS_TOKEN]
self.eos = vocab[EOS_TOKEN]
for sentence in tqdm(corpus, desc="Dataset Construction"):
sentence = [self.bos] + sentence + [self.eos]
for i in range(1, len(sentence)-1):
w = sentence[i]
left_contexts = sentence[max(0, i - context_size):i]
right_contexts = sentence[i+1:min(len(sentence), i + context_size)+1]
# 共现次数随距离衰减: 1/d(w, c)
for k, c in enumerate(left_contexts[::-1]):
self.cooccur_counts[(w, c)] += 1 / (k + 1)
for k, c in enumerate(right_contexts):
self.cooccur_counts[(w, c)] += 1 / (k + 1)
self.data = [(w, c, count) for (w, c), count in self.cooccur_counts.items()]模型
GloVe模型与基于负采样的Skip-gram模型类似,唯一的区别在于 增加了两个偏置向量 ,具体代码如下。
class GloveModel(nn.Module):
def __init__(self, vocab_size, embedding_dim):
super(GloveModel, self).__init__()
# 词嵌入及偏置向量
self.w_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.w_biases = nn.Embedding(vocab_size, 1)
# 上下文嵌入及偏置向量
self.c_embeddings = nn.Embedding(vocab_size, embedding_dim)
self.c_biases = nn.Embedding(vocab_size, 1)
def forward_w(self, words):
w_embeds = self.w_embeddings(words)
w_biases = self.w_biases(words)
return w_embeds, w_biases
def forward_c(self, contexts):
c_embeds = self.c_embeddings(contexts)
c_biases = self.c_biases(contexts)
return c_embeds, c_biases训练
# 用以控制样本权重的超参数
m_max = 100
alpha = 0.75
# 从文本数据中构建GloVe训练数据集
corpus, vocab = load_reuters()
dataset = GloveDataset(
corpus,
vocab,
context_size=context_size
)
data_loader = get_loader(dataset, batch_size)
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = GloveModel(len(vocab), embedding_dim)
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=0.001)
model.train()
for epoch in range(num_epoch):
total_loss = 0
for batch in tqdm(data_loader, desc=f"Training Epoch {epoch}"):
words, contexts, counts = [x.to(device) for x in batch]
# 提取batch内词、上下文的向量表示及偏置
word_embeds, word_biases = model.forward_w(words)
context_embeds, context_biases = model.forward_c(contexts)
# 回归目标值:必要时可以使用log(counts+1)进行平滑
log_counts = torch.log(counts)
# 样本权重
weight_factor = torch.clamp(torch.pow(counts / m_max, alpha), max=1.0)
optimizer.zero_grad()
# 计算batch内每个样本的L2损失
loss = (torch.sum(word_embeds * context_embeds, dim=1) + word_biases + context_biases - log_counts) ** 2
# 样本加权损失
wavg_loss = (weight_factor * loss).mean()
wavg_loss.backward()
optimizer.step()
total_loss += wavg_loss.item()
print(f"Loss: {total_loss:.2f}")
# 合并词嵌入矩阵与上下文嵌入矩阵,作为最终的预训练词向量
combined_embeds = model.w_embeddings.weight + model.c_embeddings.weight
save_pretrained(vocab, combined_embeds.data, "glove.vec")内部评价方法
词的相关性

def knn(W, x, k):
#计算查询向量x与矩阵w中每一个行向量之间的余弦相似度,
#并返回相似度最高的k个向量
similarities = torch.matmul(x, W.transpose(1, 0)) / (torch.norm(W, dim=1) * torch.norm(x) + 1e-9)
knn = similarities.topk(k=k)
return knn.values.tolist(), knn.indices.tolist()利用该函数,可实现在词向量空间内进行近义词检索。
def find_similar_words(embeds, vocab, query, k=5):
knn_values, knn_indices = knn(embeds, embeds[vocab[query]], k + 1)
knn_words = vocab.convert_ids_to_tokens(knn_indices)
print(f">>> Query word: {query}")
for i in range(k):
print(f"cosine similarity={knn_values[i + 1]:.4f}: {knn_words[i + 1]}")加载斯坦福大学发布的Glove预训练词向量,下载好词向量之后,使用 load_pretrained 函数进行加载,并返回词表与词向量对象。
def load_pretrained(load_path):
with open(load_path, "r") as fin:
# Optional: depending on the specific format of pretrained vector file
n, d = map(int, fin.readline().split())
tokens = []
embeds = []
for line in fin:
line = line.rstrip().split(' ')
token, embed = line[0], list(map(float, line[1:]))
tokens.append(token)
embeds.append(embed)
vocab = Vocab(tokens)
embeds = torch.tensor(embeds, dtype=torch.float)
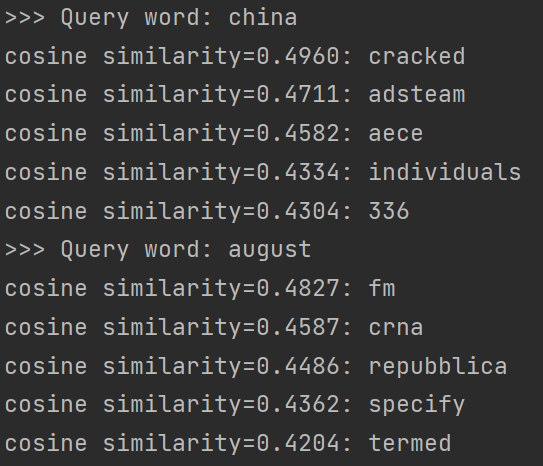
return vocab, embeds在GloVe词向量空间内以“china”“august”为查询词进行近义词检索,可以得到以下结果。
类比性
对于语法或者语义关系相同的两个词 ,词向量在一定程度上满足
,词向量在一定程度上满足
 ≈
≈
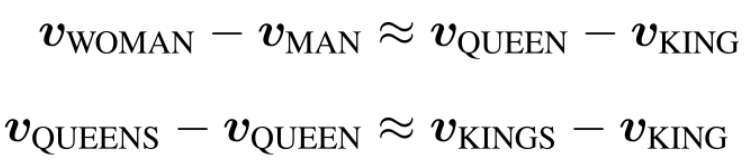
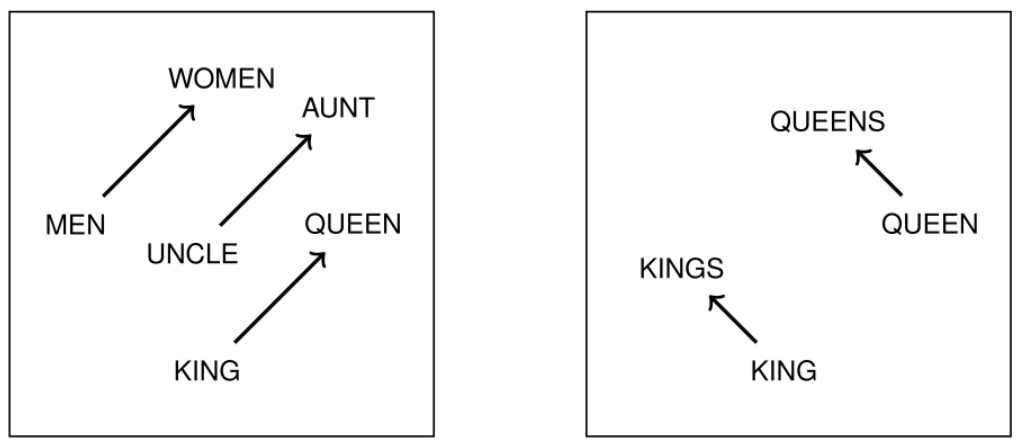
词向量空间内的语义和语法类比推理性质示例
这两个例子分别从词义和词法两个角度展示了词向量的类比性利用这个可以进行词与词之间的关系推理,回答诸如 “a 之于 b 相当于 c 之于 ?”等问题。对于下画线处的词,可以利用下式的词向量空间内搜索得到

def find_analogy(embeds, vocab, word_a, word_b, word_c):
vecs = embeds[vocab.convert_tokens_to_ids([word_a, word_b, word_c])]
x = vecs[2] + vecs[1] - vecs[0]
knn_values, knn_indices = knn(embeds, x, k=1)
analogies = vocab.convert_ids_to_tokens(knn_indices)
print(f">>> Query: {word_a}, {word_b}, {word_c}")
print(f"{analogies}")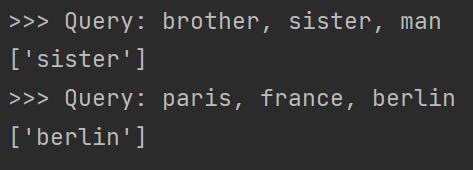
上述结果显然效果欠佳,需要语料库的大小越大越好。
外部评价方法
根据下游任务的性能指标判断

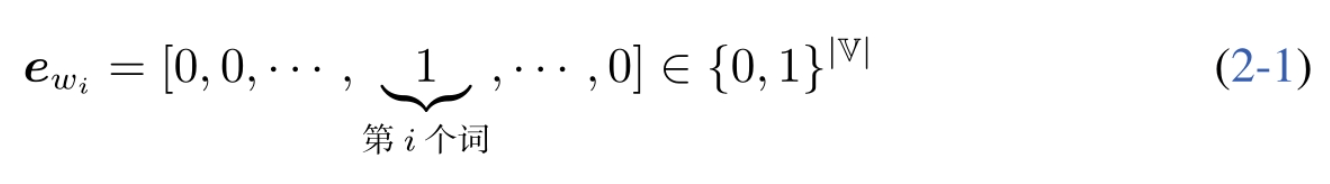

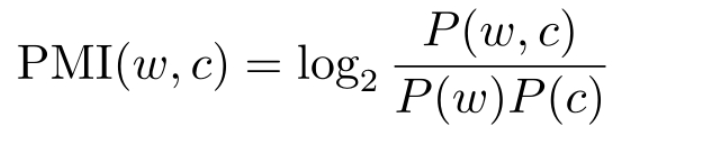
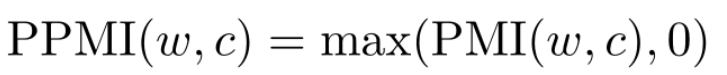
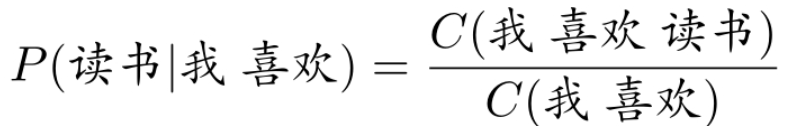
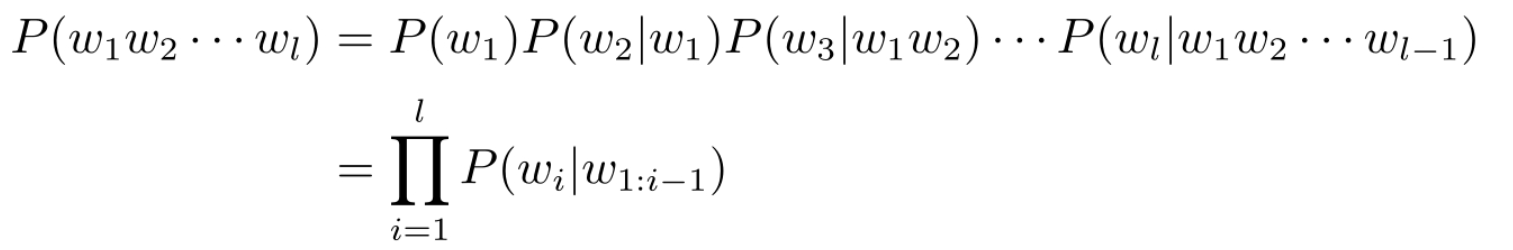


 可以是
可以是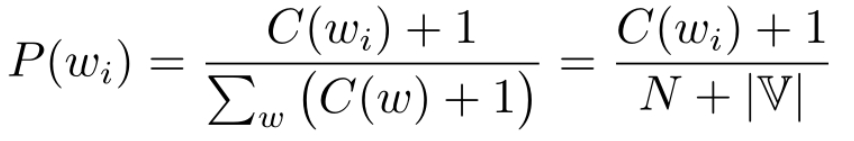
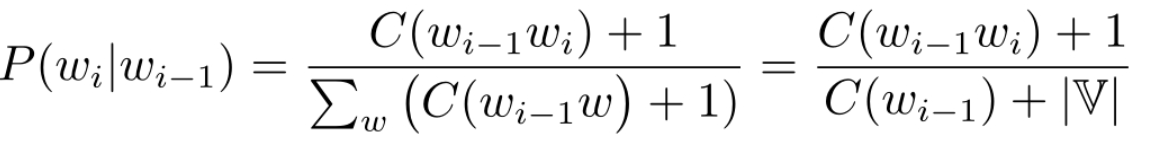


 : 测试集到每个词的概率的几何平均值的倒数
: 测试集到每个词的概率的几何平均值的倒数






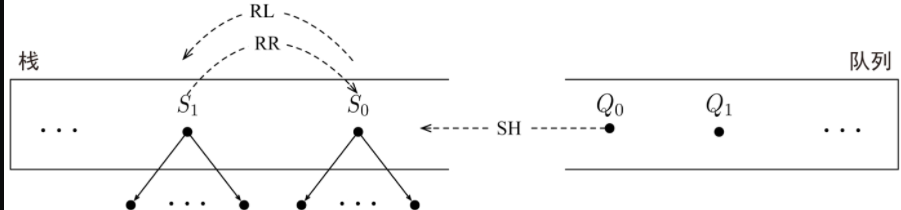
 和队列组成, 栈存依存结构子树序列,队列存未处理的词
和队列组成, 栈存依存结构子树序列,队列存未处理的词