书名:自然语言处理:基于预训练模型的方法

文本的表示
独热编码表示
独热编码,就是使用一个词表的大小的向量表示一个词的“语义”,然后第i个词用wi表示。词表中第i个词在第i维上被设置为1,其余维均为0。
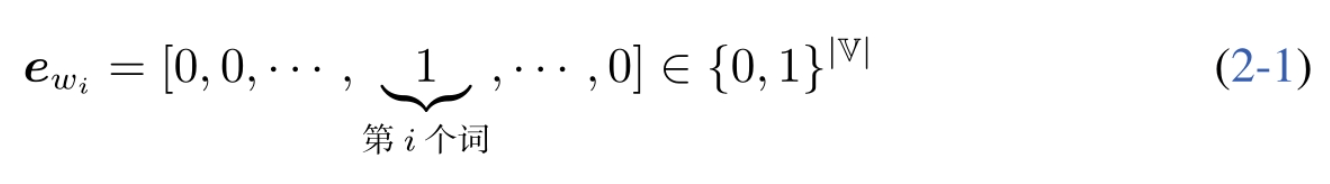
词的分布式表示
由于用独热编码表示词汇导致数据过于稀疏和庞大。因此John RupertFirth于1957年提出了分布式语义假设:词的含义可由其上下文的分布进行表示。

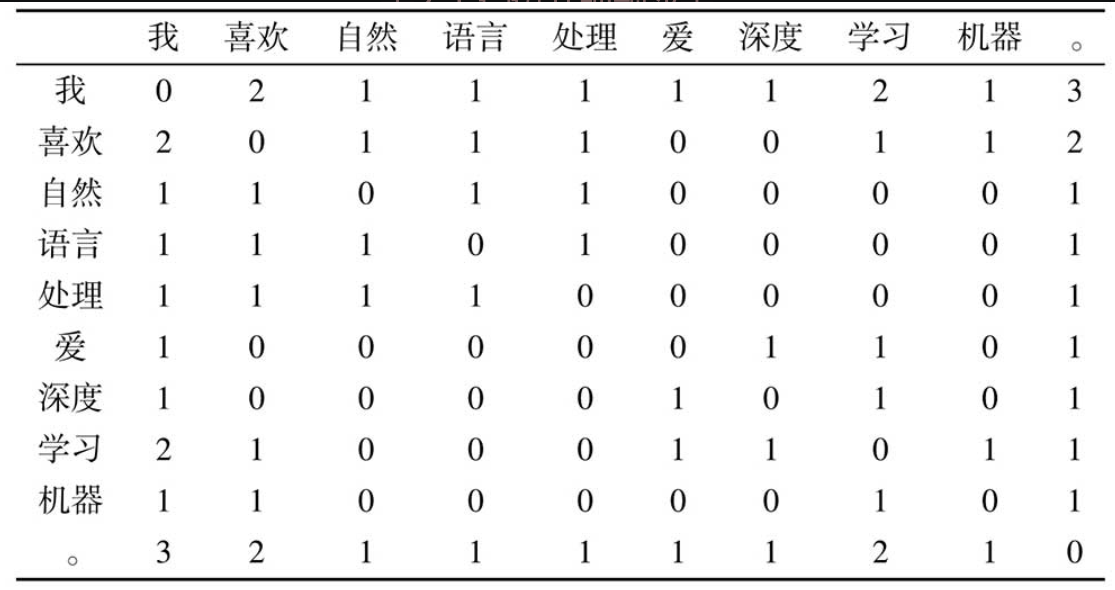
我们将以词为单位的其它词语作为上下文,因此创建下列共现频次表。
除了词,上下文的选择有很多种方式,而选择不同的上下文得到的词向量表示性质会有所不同。例如,可以使用词在句子中的一个固定窗口内的词作为其上下文,也可以使用所在的文档本身作为上下文。前者得到的词表示将更多地反映词的局部性质:具有相似词法、句法属性的词将会具有相似的向量表示。而后者将更多地反映词代表的主题信息。
直接使用与上下文的共现频次作为词的向量表示,至少存在以下三个问题:
- 高频词往往没有什么作用,反而会影响计算机国。如"我" "。"的共现频次很高,实际上可能它们并没有关系但由于共现过,从而产生了较高的相似度。
- 共现频次无法反映词之前的高阶关系。假设词“A”与“B”共现过,“B”与“C”共现过,“C”与“D”共现过,通过共现频次,只能获知“A”与“C”都与“B”共现过,它们之间存在一定的关系,而“A”与“D”这种高阶的关系则无法知晓。
- 仍然存在稀疏性的问题。即向量中仍有大量的值为0
解决高频词误导计算结果的问题
点互信息
由于共矩阵仍然存在稀疏性的问题。即向量中仍有大量的值为0。最直接的想法就是:如果一个词与很多词共现,则降低其权重;反之,如果一个词只与个别词共现,则提高其权重。信息论中的点互信息(Pointwise Mutual Information,PMI)恰好能够做到这一点。
对于词w和上下文c,其PMI为:
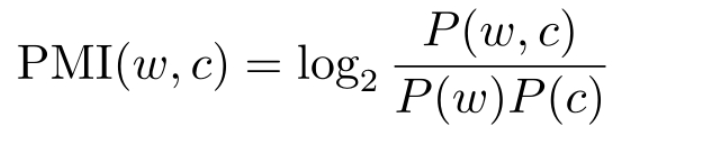
式中,P (w, c)、P (w)、P (c)分别是w与c的共现概率,以及w和c分别出现的概率。可见,通过PMI公式计算,如果w和c的共现概率(与频次正相关)较高,但是w或者c出现的概率也较高(高频词),则最终的PMI值会变小;反之,即便w和c的共现概率不高,但是w或者c出现的概率较低(低频词),则最终的PMI值也可能会比较大。从而较好地解决高频词误导计算结果的问题。
当某个词与上下文之间共现次数较低时,可能会得到负的PMI值。考虑到这种情况下的PMI不太稳定(具有较大的方差),在实际应用中通常采用PPMI (Positive PMI)的形式,即:
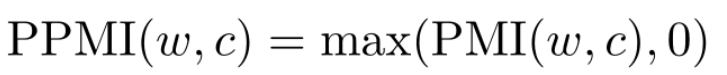
奇异值分解
解决共现频次无法反映词之间高阶关系的问题。相关的技术有很多,对共现矩阵M进行奇异值分解。
词的分布式表示取得了不错的效果,但是其仍然存在一些问题。
- 当共现矩阵规模较大时,奇异值分解的运行速度非常慢;
- 如果想在原来语料库的基础上增加更多的数据,则需要重新运行奇异值分解算法,代价非常高;
- 分布式表示只能用于表示比较短的单元,如词或短语等,如果待表示的单元比较长,如段落、句子等,由于与其共现的上下文会非常少,则无法获得有效的分布式表示;
- 最后,分布式表示一旦训练完成,则无法修改,也就是说,无法根据具体的任务调整其表示方式。为了解决这些问题,可引入一种新的词表示方式——词嵌入表示。
词嵌入表示(Word Embedding)
使用一个连续、低维、稠密的向量来表示词,经常直接简称为词向量
词向量中的向量值,是随着目标任务的优化过程自动调整的,也就是说,可以将词向量中的向量值看作模型的参数
词袋表示
所谓词袋表示,就是假设文本中的词语是没有顺序的集合,将文本中的全部词所对应的向量表示(既可以是独热表示,也可以是分布式表示或词向量)相加,即构成了文本的向量表示。如在使用独热表示时,文本向量表示的每一维恰好是相应的词在文本中出现的次数。
nlp任务
语言模型(统计语言模型)
N元语言模型
基本任务是在给定词序列w1w2··· wt−1的条件下,对下一时刻t可能出现的词wt的条件概率P (wt|w1w2···wt−1)进行估计。一般地,把w1w2··· wt−1称为wt的历史。
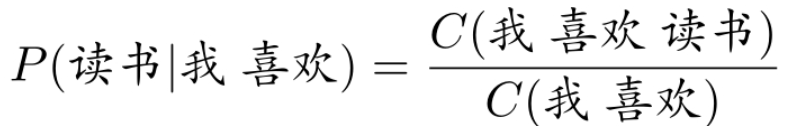
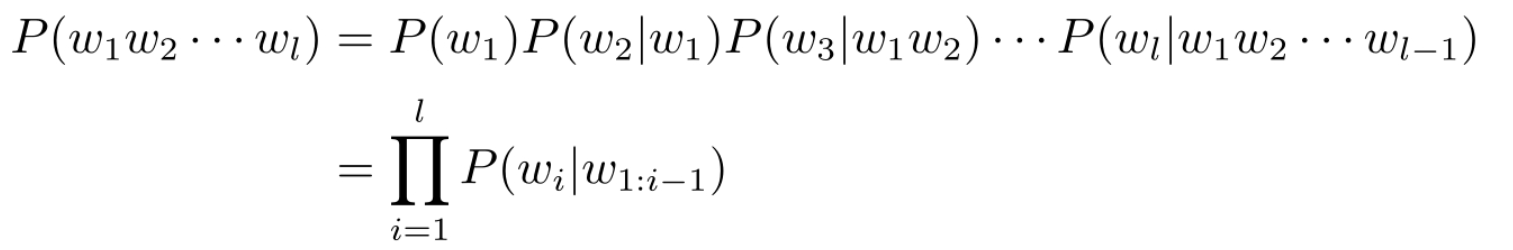
随着句子长度增加,w1:i−1出现的次数会越来越少,甚至从未出现过,那么P (wi|w1:i−1)则很可能为0,此时对于概率估计就没有意义了。为了解决该问题,可以假设“下一个词出现的概率只依赖于它前面n−1个词”。
马尔可夫假设
- N-gram :N 元语言模型
- 马尔可夫假设 :

- 满足该假设称为:N元语法或文法(gram)模型
- n=1 的 unigram 独立于历史(之前的序列),因此语序无关
- n=2 的 bigram 也被称为一阶马尔可夫链

- w0 可以是 ,
 可以是
可以是
- 平滑: 解决未登录词 (OOV, Out-Of-Vocabulary, )的零概率问题
- 折扣法 :高频补低频(频繁出现的N-gram中匀出一部分概率并分配给低频次(含零频次)的N-gram)
- 加1平滑 :拉普拉斯平滑
对于unigram: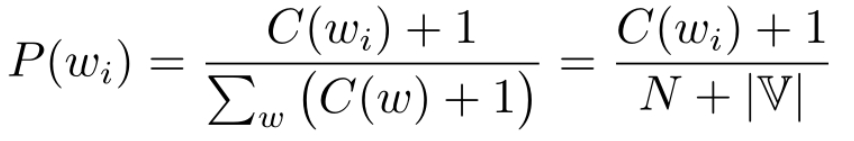
对于biggram: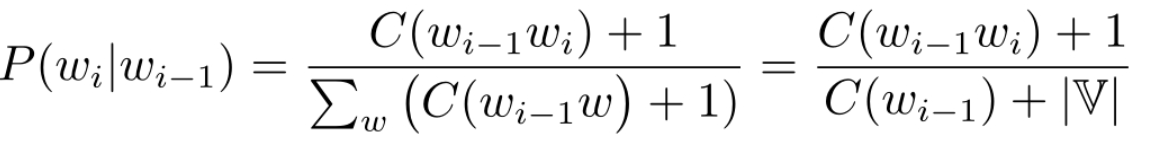
也可以使用 +δ 平滑,尤其当训练数据较小时,加一太大了
关于 δ 选择,可以使用验证集对不同值的困惑度比较选择最优参数
- 模型评价
1.外部任务评价:计算代价高,实现的难度较大
2.内部评价方法: 基于困惑度 (Perplexity, PPL) ,越小越好


 : 测试集到每个词的概率的几何平均值的倒数
: 测试集到每个词的概率的几何平均值的倒数
测试集到每个词这里针对一个句子而言:我们的目标是使测试集中的所有句子 PPL 最小。
困惑度越低的语言模型并不总是能在外部任务上取得更好的性能指标,但是两者之间通常呈现出一定的正相关性。应用在下游任务之后,关键要看具体任务上的表现。
基础任务
中文分词
- 正向最多匹配算法(FMM),找当前最长词
- 可能会造成切分歧义问题:如“哈尔滨市”可以是一个词,也可以认为“哈尔滨”是一个词,“市”是一个词。
- 未登录词的问题比例更高:未登录词指不在词典中,但是必须要分出来的词
字词切分:词形还原(Lemmatization)或者词干提取(Stemming)
词形还原指的是将变形的词语转换为原形,如将“computing”还原为“compute”;
词干提取则是将前缀、后缀等去掉,保留词干(Stem),如“computing”的词干为“comput”,可见,词干提取的结果可能不是一个完整的单词。
- 解决数据稀疏问题和大词表问题
- 传统方法需要大量规则,因此:基于统计的无监督方法(使用尽量长且频次高的子词)
- 字节对编码 (BPE)生成子词词表,然后使用贪心算法;可以使用缓存算法加快速度
- WordPiece: 比对BPE, 不过 BPE 选频次最高对,WordPiece 选提升语言模型概率最大对。
- Unigram Language Model (ULM) : 比对WordPiece, 不同的是,它基于减量法
SentencePiece 开源工具用于子词切分,通过将句子看做 Unicode ,从而能够处理多种语言
词性标注
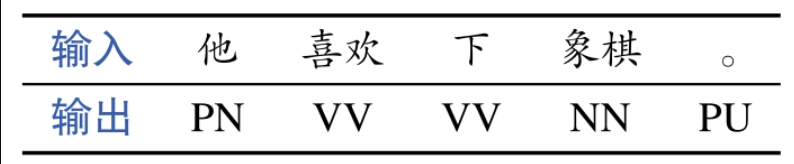
词性标注(POS Tagging)任务是指给定一个句子,输出句子中每个词相应的词性。
例如,当输入句子为:"他 喜欢 下 象棋"
输出:他/PN 喜欢/VV 下/VV 象棋/NN 。/PU
斜杠后面的PN、VV、NN和PU分别代表代词、动词、名词和标点符号
难点在于歧义性,即一个词在不同的上下文中可能有不同的词性。例如,上例中的“下”,既可以表示动词,也可以表示方位词。因此,需要结合上下文确定词在句子中的具体词性。
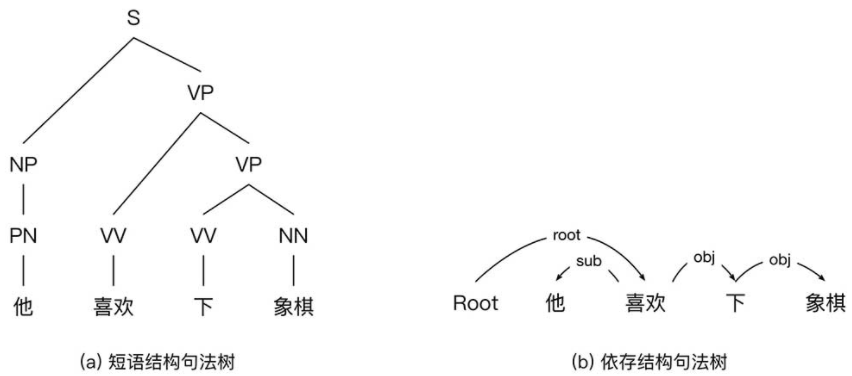
句法分析
句法分析(Syntactic Parsing)的主要目标是给定一个句子,分析句子的句法成分信息,例如主谓宾定状补等成分。
最终的目标是将词序列表示的句子转换成树状结构,从而有助于更准确地理解句子的含义,并辅助下游自然语言处理任务
- 树状结构的主谓宾定状补等
两种句法结构表示:不同点在于依托的文法规则不同
- 短语结构句法表示:上下文无关文法,层次性的表示法
- 依存结构句法表示 (DSP):依托依存文法规则
语义分析
词义消歧WSD
从词语的粒度考虑,一个词语可能具有多种语义(词义),例如“打”,含义即可能是“攻击”(如“打人”),还可能是“玩”(如“打篮球”),甚至“编织”(如“打毛衣”)等。根据词语出现的不同上下文,确定其具体含义的自然语言处理任务被称为词义消歧(Word SenseDisambiguation,WSD)。可以使用 WordNet 等语义词典
语义角色标注 SRL : 谓词论元结构
识别谓词后找到论元(语义角色)(施事 Agent 受事 Patient)
附加语义角色: 状语、副词等
语义依存分析SDP:通用图
- 语义依存图:词作为节点,词词关系作为语义关系边
- 概念语义图:首先将句子转化为虚拟的概念节点,然后建立语义关系边
专门任务:如自然语言转 SQL
应用任务
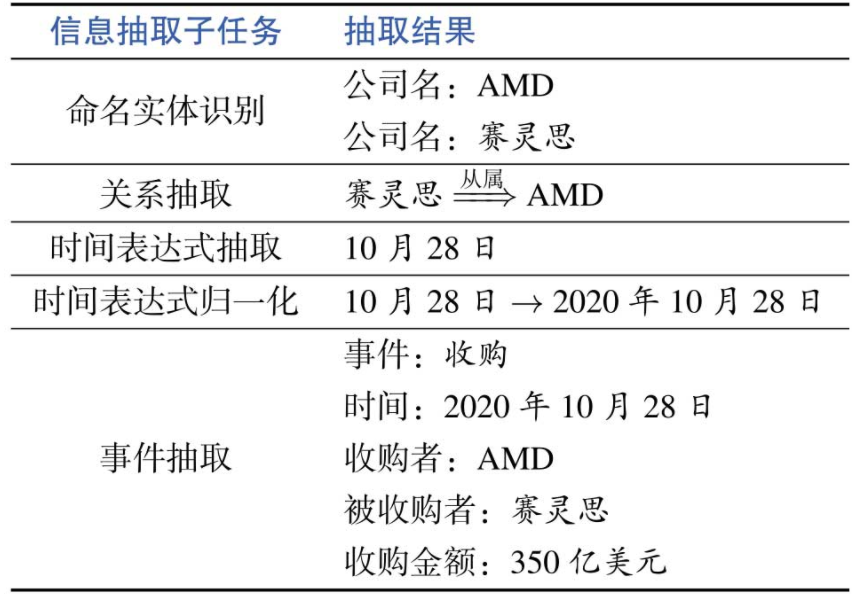
信息抽取(Information Extraction,IE)
信息抽取 ,定义:从非结构化的文本中自动提取结构化信息的过程,另外还可以将抽取的记过作为新的知识加入知识库中。
命名实体识别(Information Extraction,IE)
定义:在文本中抽取每个提及的命名实体并标注其类型,一般包括人名、地名和机构名等,也包括专有名称等,如书名、电影名和药物名等。然后往往需要将命名实体链接到知识库或者知识图谱中的具体实体,被称作 实体链接 。
如“华盛顿”既可以指美国首任总统,也可以指美国首都,需要根据上下文进行判断,这一过程类似于词义消歧任务。
关系抽取(Relation Extraction)
定义:用于识别和分类文本中提及的实体之间的语义关系,如夫妻、子女、工作单位和地理空间上的位置关系等二元关系。
事件抽取(Event Extraction)
从文本中识别人们感兴趣的事件以及事件所涉及的时间、地点和人物等关键元素。事件往往使用文本中提及的具体触发词(Trigger)定义,解析时间、地点、人物等关键因素。
时间表达式(Temporal Expression)
事件发生的时间往往比较关键,通常时间表达式识别被认为是重要的信息抽取子任务。
绝对时间:日期、星期、月份和节假日等
相对时间:明天、两年前等
~SRL : 谓词~Trigger, 论元~事件元素
假设下列句子进行信息抽取

信息抽取结果
情感分析
- 情感分类(识别文本中蕴含的情感类型或者情感强度,其中,文本既可以是句子,也可以是篇章)
- 情感信息抽取(抽取文本中的情感元素,如评价词语、评价对象和评价搭配等)
如图中用户评论
情感分析结果如下:

问答系统(Question Answering,QA)
系统接收用户以自然语言形式描述问题,并从异构数据中通过检索、匹配和推理等技术获得答案的自然语言处理系统。
根据数据来源的不同,问答系统可以分为4种主要的类型:
- 检索式:答案来源于归哪个的文本预料库,系统查找相关文档抽取答案并完成回答
- 知识库:问题→结构化查询语句 →结构化知识存储→推理→答案
- 常见问题集:对历史积累的常见问题集检索,回答用户提出的类似问题
- 阅读理解式:抽取给定文档中片段或生成
机器翻译(Machine Translation,MT)
对话系统
用户与计算机通过多轮交互的方式实现特定目标的智能系统。
- 任务型:垂直领域的自动业务经理,具有明确的任务目标,如完成机票预订、天气查询等特定的任务。
自然语言理解→对话管理→自然语言生成
NLU : 领域(什么东西)、意图(要干什么)、槽值(?=?)等
DM : 对话状态跟踪 DST 和对话策略优化 DPO,对话状态往往表示为槽值列表
NLG : 有了 DPO 后比较简单,只需要套用问题模板即可

- 开放域:聊天系统或者聊天机器人

基本问题
文本分类问题
定义:针对一段文本输入,输出该文本所属的类别
- 文本匹配(Text Matching),即判断两段输入文本之间的匹配关系,包括复述关系(Paraphrasing:判断两个表述不同的文本语义是否相同)
- 蕴含关系(Entailment:根据一个前提文本,推断与假设文本之间的蕴含或矛盾关系)等。一种转换的方法是将两段文本直接拼接起来,然后按复述或非复述、蕴含或矛盾等关系分类。
结构预测问题
序列标注(Sqquence Labeling)
为输入文本序列中的每个词标注相应的标签,如词性标注是为每个词标注一个词性标签,包括名词、动词和形容词等。其中,输入词和输出标签数目相同且一一对应。
序列标注问题可以简单地看成多个独立的文本分类问题,即针对每个词提取特征,然后进行标签分类,并不考虑输出标签之间的关系。
- CRF模型:最广泛应用的序列标注模型,他不仅考虑每个词属于某一标签的概率(发射概率),还考虑标签之间的相互关系(转移概率)。
- RNN(循环神经网络)+CRF(条件随机场)
序列分割
NER : B-xxx 表示开始,I-xxx 表示中间,O-xxx 表示非实体
分词同理
图结构生成
- 基于图的算法:最小生成树,最小子图等
- 基于转移的算法:图→ 状态转移序列,状态→策略→动作等。
使用序列标注方法解决序列分割(分词和命名实体识别)

如用于 DSP 的 标准弧转移算法 :
转移状态由一个栈 和队列组成, 栈存依存结构子树序列,队列存未处理的词
和队列组成, 栈存依存结构子树序列,队列存未处理的词
初始转移状态:栈为空
转移动作:
- 移进 Shift (SH) : 将队列中的第一个元素移入栈顶,形成一个仅包含一个节点的依存子树
- 左弧归约 Reduce Left (RL) : 将栈顶的两棵依存子树采用一个左弧S1↶S0进行合并,然后S1下栈;
- 将栈顶的两棵依存子树采用一个右弧S1↷S0进行合并,然后S0下栈。
- 完成 FIN
弧上的句法关系可以在生成弧的时候(即 RR 或 RL)采用额外的句法关系分类器加以预测
该算法也可以用于短语结构的句法分析方法
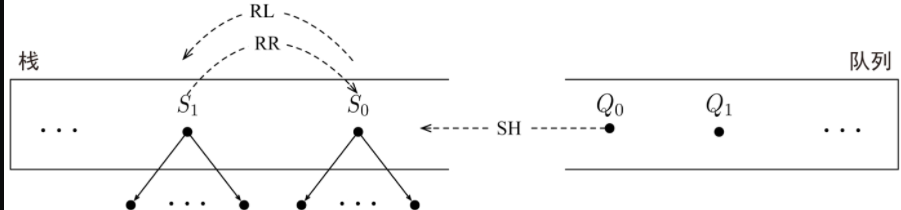
面向依存句法分析的标准弧转移算法中的三种动作
序列到序列问题
Encoder-Decoder架构
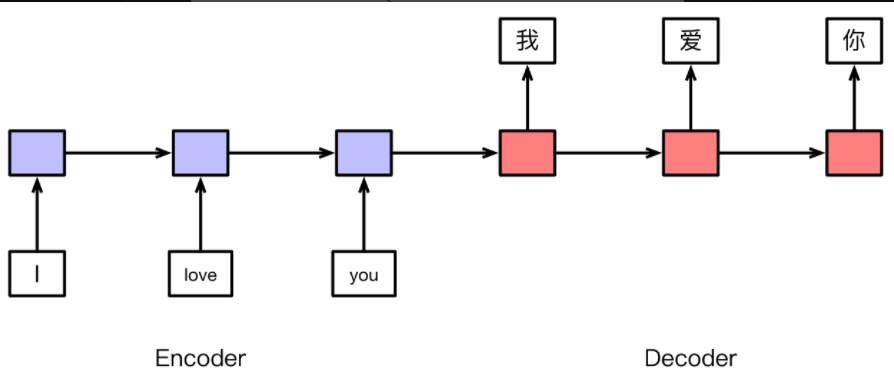
评价指标
准确率(Accuracy)
最简单、直观的评价指标,经常被应用于文本分类等问题。其计算公式为:

词性标注等序列标注问题也可以采用准确率进行评价,即:

并非全部的序列标注问题都可以采用准确率进行评价,如在将分词、命名实体识别等序列分割问题转化为序列标注问题后,就不应该使用准确率进行评价。
命名实体识别,序列标注的输出标签可以为一个实体的开始(B-XXX)、中间(I-XXX)或者非实体(O)等,其中B代表开始(Begin)、I代表中间(Inside),O代表其他(Other),XXX代表实体的类型,如人名(PER)、地名(LOC)和机构名(ORG)等
F -score
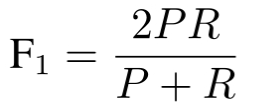
- Ner中:

- 在句法依存树中:
- UAS :(unlabeled attachment score): 即准确率,父节点被正确识别的概率
- LAS :父节点被正确识别且与父节点的关系也正确的概率
- 在 Semantic Dependency Graph :多个父节点不能用上述
- F-score : 图中的弧为单位,计算识别的精确率和召回率
- 可分为考虑和不考虑语义关系两种情况
- 在短语结构句法分析中:也不能用准确率
- F-score : 句法结构中包含短语的 F 值进行评价
- 包含短语:包括短语类型以及短语所覆盖的范围

































