第十届“泰迪杯”数据挖掘挑战赛:疫情背景下的周边游需求图谱分析-国二方案分享(2)
第十届“泰迪杯”数据挖掘挑战赛C题 -疫情背景下的周边游需求图谱分析 第2问和第3问 产品热度计算方法
第一问分享在下列链接:[post cid="161" cover="" size=""/]
[scode type="green" size="simple"]
我已在AIStudio将赛题方案上传,可以一键Fork运行。
步骤:未注册的小伙伴需要先去AI Studio进行注册,完善资料后,访问下面方案链接(觉得好的话,记得给我点个关注和小红心哦):
由于该赛题方案内容太多,故将1问和2、3问分开分享
竞赛地址:https://www.tipdm.org:10010/#/competition/1481159137780998144/question
[/scode]
一、项目介绍
- 1.1 赛题背景
- 1.2 第二问拟解决的问题 周边游产品热度分析
- 1.3 第三问拟解决的问题 本地旅游图谱构建与分析
二、方案设计
- 2.1 赛题背景
- 2.2 第二问拟解决的问题 周边游产品热度分析
三、基于SKEP的周边游产品热度评价
- 3.1 评论观点抽取模型
- 3.2 属性级情感分类模型
- 3.3 全流程模型推理
四、 计算产品热度
- 4.1 方面级情感极性预测及计算情感分数
- 4.2统计产品情感热度得分
- 五、致谢
一、 项目介绍
1.1 赛题背景
随着互联网和自媒体的繁荣,文本形式的在线旅游(Online Travel Agency,OTA)和游客的用户生成内容(User Generated Content,UGC)数据成为了解旅游市场现状的重要信息来源。OTA和UGC数据的内容较为分散和碎片化,要使用它们对某一特定旅游目的地进行研究时,迫切需要一种能够从文本中抽取相关的旅游要素,并挖掘要素之间的相关性和隐含的高层概念的可视化分析工具。
为此本赛题提出本地旅游图谱这一概念,它在通用知识图谱的基础上加入了更多针对旅游行业的需求。本地旅游图谱采用图的形式直观全面地展示特定旅游目的地“吃住行娱购游”等旅游要素,以及它们之间的关联。图 1所示为我国西藏阿里地区的本地旅游图谱,中心位置节点为旅游目的地“阿里”,它的下层要素包括该地区的重要景点如“冈仁波齐”和“玛旁雍错”,以及“安全”、“住宿”等旅游要素。旅游要素分为多个等级,需要从文本中挖掘出面对不同要素游客所关注的下一级要素。如阿里地区的“安全”要素下包括“高反”、“天气”和“季节”等下一级要素,这个组合是西藏旅游所特有的。旅游要素之间会存在关联关系,如“冈仁波齐”和“玛旁雍错”这两个景点通过“神山圣湖”这一高层概念产生联系,在本地旅游图谱中使用连接两个节点的一条边来表示。
在近年来新冠疫情常态化防控的背景下,我国游客的旅游消费方式已经发生明显的转变。在出境游停滞,跨省游时常因为零散疫情的影响被叫停的情况下,中长程旅游受到非常大的冲击,游客更多选择短程旅游,本地周边游规模暴涨迎来了风口。疫情防控常态化背景下研究分析游客消费需求行为的变化,对于旅游企业产品供给、资源优化配置以及市场持续开拓具有长远而积极的作用。本赛题提供收集自互联网公开渠道的2018年至2021年广东省茂名市的OTA和UGC数据,期待参赛者采用自然语言处理等数据挖掘方法通过建立本地旅游图谱的方式来分析新冠疫情时期该市周边游的发展。
1.2 第二问拟解决的问题 周边游产品热度分析
从附件提供的OTA、UGC数据中提取包括景区、酒店、网红景点、民宿、特色餐饮、乡村旅游、文创等旅游产品的实例和其他有用信息,将提取出的旅游产品和所依托的语料以表2的形式保存为文件“result2-1.csv”。建立旅游产品的多维度热度评价模型,对提取出的旅游产品按年度进行热度分析,并排名。将结果以表3的形式保存为文件“result2-2.csv”。
1.3 第三问拟解决的问题 本地旅游图谱构建与分析
依据提供的OTA、UGC数据,对问题2中提取出的旅游产品进行关联分析,找出以景区、酒店、餐饮等为核心的强关联模式,结果以表4的形式保存为文件“result3.csv”。在此基础上构建本地旅游图谱并选择合适方法进行可视化分析。鼓励参赛队挖掘旅游产品间隐含的关联模式并进行解释。
二. 方案设计
C题第二问
通过构建基于 SBERT 的旅游产品提取模型,对旅游攻略及微信公众号进行产品抽取,再针对情感热度问题,构建基于迁移学习与细粒度情感分析的情感热度分析模型,得出每个产品的情感分数,最终利用情感分数以及年度的产品频次按照自定的产品热度公式进行计算,最终生成年度产品热度。
本实践的解决方案采用skep模型,大致分为两个环节,首先需要进行评论观点抽取,接下来,便可以根据该评论观点去分析相应观点的情感极性。
2.1 评论观点抽取
在本实践中,我们将采用序列标注的方式进行评论观点抽取,具体而言,会抽取评论中的属性以及属性对应的观点,为此我们基于BIO的序列标注体系进行了标签的拓展:B-Aspect, I-Aspect, B-Opinion, I-Opinion, O,其中前两者用于标注评论属性,后两者用于标注相应观点。
如图1所示,首先将文本串传入SKEP模型中,利用SKEP模型对该文本串进行语义编码后,然后基于每个位置的输出去预测相应的标签。
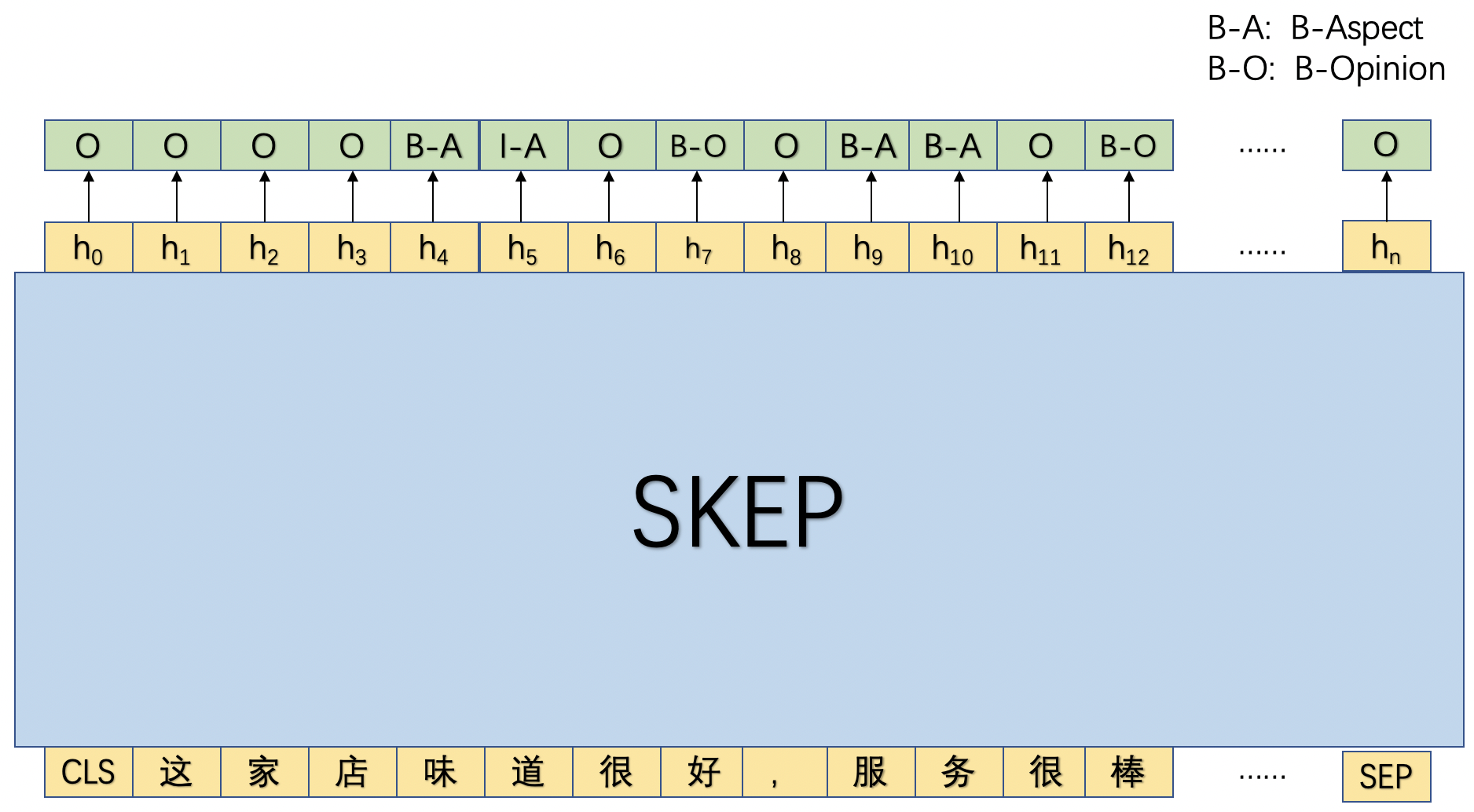
**
**
2.2 属性级情感分类
在抽取完评论观点之后,便可以有针对性的对各个属性进行评论。具体来讲,本实践将抽取出的评论属性和评论观点进行拼接,然后和原始语句进行拼接作为一条独立的训练语句。
如图2所示,首先将评论属性和观点词进行拼接为"味道好",然后将"味道好"和原文进行拼接,然后传入SKEP模型,并使用"CLS"位置的向量进行细粒度情感倾向。
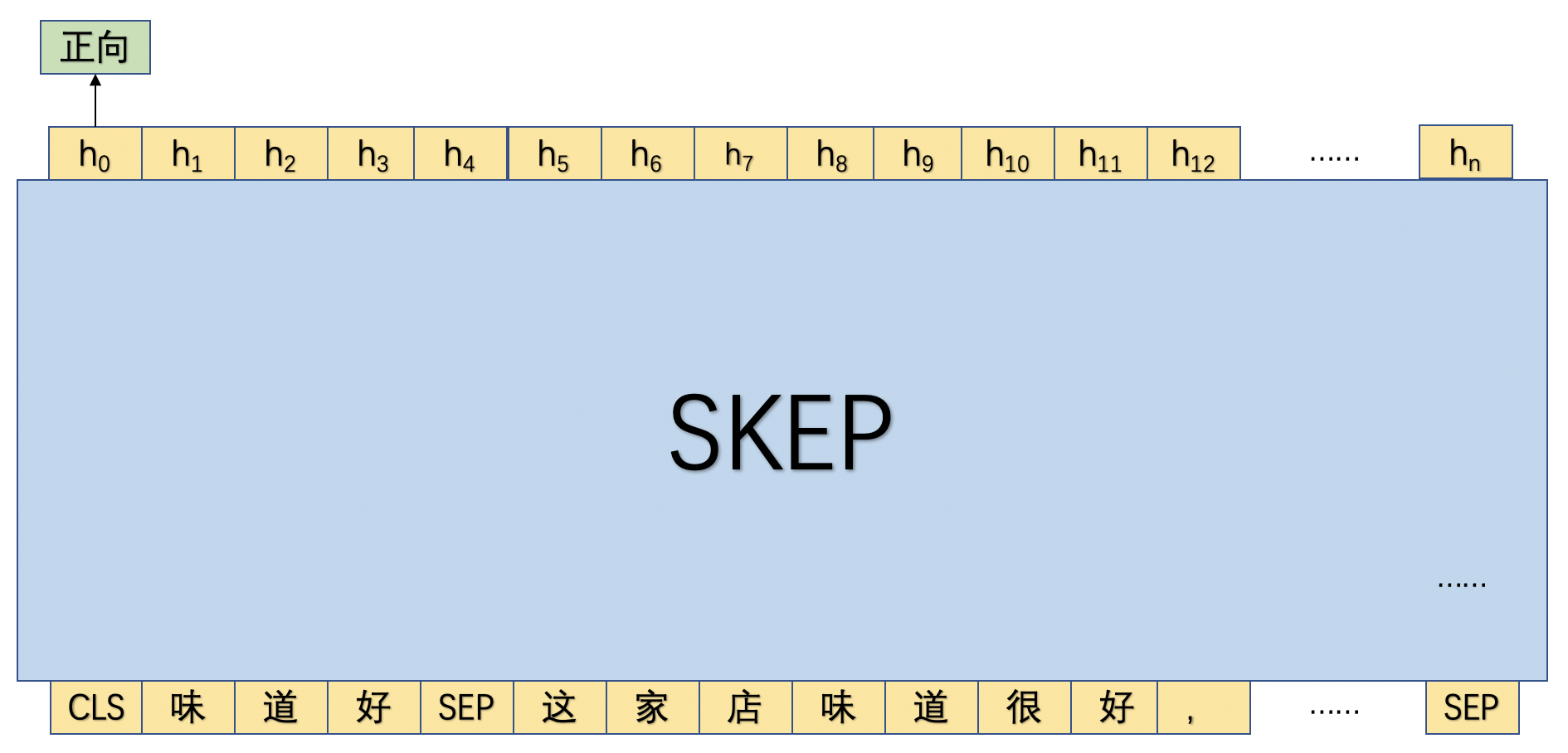
**
**
三、基于SKEP的周边游产品热度评价
3.1 评论观点抽取模型
3.1.1数据预处理
(1) 数据集介绍
本实践中包含训练集、评估和测试3项数据集,以及1个标签词典。其中标签词典记录了本实践中用于抽取评论对象和观点词时使用的标签。
另外,本实践将采用序列标注的方式完成此任务,所以本数据集中需要包含两列数据:文本串和相应的序列标签数据,下面给出了一条样本。
服务好,环境好,做出来效果也不错 B-Aspect I-Aspect B-Opinion O B-Aspect I-Aspect B-Opinion O O O O B-Aspect I-Aspect O B-Opinion I-Opinion
(2)数据加载
本节我们将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:
import os
import zipfile
def zip_decompress(file_path, new_path):
'''支持中文的解压缩程序
file_path:原zip文件路径
new_path:新文件夹路径
'''
z = zipfile.ZipFile(f'{file_path}', 'r')
z.extractall(path=f"{new_path}")
for root,dirs,files in os.walk(new_path):
for d in dirs:
try:
new_name = f.encode('cp437').decode('utf-8')
os.rename(os.path.join(root, d), os.path.join(root, new_dname))
except:
new_dname = d.encode('cp437').decode('utf-8')
os.rename(os.path.join(root, d), os.path.join(root, new_dname))
for root,dirs,files in os.walk(new_path):
for f in files:
try:
new_name = f.encode('cp437').decode('utf-8')
os.rename(os.path.join(root, f), os.path.join(root, new_name))
except:
new_name = f.encode('cp437').decode('utf-8')
os.rename(os.path.join(root, f), os.path.join(root, new_name))
z.close()
# print('完成!')
zip_decompress("./data/CEC-Corpus-master.zip","./data/CEC")import xml.dom.minidom
import os
count = [0 for i in range(4000)]
#存放xml文件的地址
xml_file_path = r"./data/CEC/CEC-Corpus-master/CEC/地震/"
lst_dir = os.listdir(xml_file_path)
for file_name in lst_dir:
#读入所有的xml文件
file_path = xml_file_path + file_name
tree = xml.dom.minidom.parse(file_path)
#获取根节点
root = tree.documentElement
#接下来就可以对指定的文本元素进行操作
size_node = root.getElementsByTagName("object")
for o in size_node:
count[i] = count[i] + 1
#有一个就数量加1
!pip install lxmlimport os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import ChunkEvaluator
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed
from utils import data_ext, data_cls
train_path = "./data/data121190/train_ext.txt"
dev_path = "./data/data121190/dev_ext.txt"
test_path = "./data/data121190/test_ext.txt"
label_path = "./data/data121190/label_ext.dict"
# load and process data
label2id, id2label = data_ext.load_dict(label_path)
train_ds = load_dataset(data_ext.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_ext.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_ext.read, data_path=test_path, lazy=False)
# print examples
for example in train_ds[9:11]:
print(example)
(3)将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。
model_name = "skep_ernie_1.0_large_ch"
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_ext.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
# print examples
for example in train_ds[9:11]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()(4)构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="int64"),
Pad(axis=0, pad_val= -1)
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(test_ds, batch_sampler=test_batch_sampler, collate_fn=batchify_fn)3.1.2模型构建
本案例中,我们将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。接下来,我们将基于该向量序列进行预测每个位置上的输出标签。相应代码如下。
class SkepForTokenClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForTokenClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
sequence_output, _ = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
sequence_output = self.dropout(sequence_output)
logits = self.classifier(sequence_output)
return logits3.1.3 训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
# model hyperparameter setting
num_epoch = 20
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = ChunkEvaluator(label2id.keys())3.1.4 模型训练与测试
本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for idx, batch_data in enumerate(data_loader):
input_ids, token_type_ids, seq_lens, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
# count metric
predictions = logits.argmax(axis=2)
num_infer_chunks, num_label_chunks, num_correct_chunks = metric.compute(seq_lens, predictions, labels)
metric.update(num_infer_chunks.numpy(), num_label_chunks.numpy(), num_correct_chunks.numpy())
precision, recall, f1 = metric.accumulate()
return precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits.reshape([-1, len(label2id)]), labels.reshape([-1]), ignore_index=-1)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_ext.pdparams")
print(f'evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_ext.pdparams")
train()接下来,我们将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。
# load model
model_path = "./checkpoint/best_ext.pdparams"
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForTokenClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)# evalute on test data
precision, recall, f1 = evaluate(model, test_loader, metric)
print(f'evalution result: precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')3. 2属性级情感分类模型
3.2.1数据预处理
(1)数据集介绍
本实践中包含训练集、评估和测试3项数据集,以及1个标签词典。其中标签词典记录了两类情感标签:正向和负向。
另外,数据集中需要包含3列数据:文本串和相应的序列标签数据,下面给出了一条样本,其中第1列是情感标签,第2列是评论属性和观点,第3列是原文。
1 口味清淡 口味很清淡,价格也比较公道
(2)数据加载
本节我们将训练、评估和测试数据集,以及标签词典加载到内存中。相关代码如下:
import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed, decoding, is_aspect_first, concate_aspect_and_opinion, format_print
from utils import data_ext, data_cls
train_path = "./data/data121242/train_cls.txt"
dev_path = "./data/data121242/dev_cls.txt"
test_path = "./data/data121242/test_cls.txt"
label_path = "./data/data121242/label_cls.dict"
# load and process data
label2id, id2label = data_cls.load_dict(label_path)
train_ds = load_dataset(data_cls.read, data_path=train_path, lazy=False)
dev_ds = load_dataset(data_cls.read, data_path=dev_path, lazy=False)
test_ds = load_dataset(data_cls.read, data_path=test_path, lazy=False)
# print examples
for example in train_ds[:2]:
print(example)import os
import argparse
from functools import partial
import paddle
import paddle.nn.functional as F
from paddlenlp.metrics import AccuracyAndF1
from paddlenlp.datasets import load_dataset
from paddlenlp.data import Pad, Stack, Tuple
from paddlenlp.transformers import SkepTokenizer, SkepModel, LinearDecayWithWarmup
from utils.utils import set_seed, decoding, is_aspect_first, concate_aspect_and_opinion, format_print
from utils import data_ext, data_cls(3)将数据转换成特征形式
在将数据加载完成后,接下来,我们将各项数据集转换成适合输入模型的特征形式,即将文本字符串数据转换成字典id的形式。这里我们要加载paddleNLP中的SkepTokenizer,其将帮助我们完成这个字符串到字典id的转换。
model_name = "skep_ernie_1.0_large_ch"
batch_size = 8
max_seq_len = 512
tokenizer = SkepTokenizer.from_pretrained(model_name)
trans_func = partial(data_cls.convert_example_to_feature, tokenizer=tokenizer, label2id=label2id, max_seq_len=max_seq_len)
train_ds = train_ds.map(trans_func, lazy=False)
dev_ds = dev_ds.map(trans_func, lazy=False)
test_ds = test_ds.map(trans_func, lazy=False)
# print examples
# print examples
for example in train_ds[:2]:
print("input_ids: ", example[0])
print("token_type_ids: ", example[1])
print("seq_len: ", example[2])
print("label: ", example[3])
print()(4)构造DataLoader
接下来,我们需要根据加载至内存的数据构造DataLoader,该DataLoader将支持以batch的形式将数据进行划分,从而以batch的形式训练相应模型。
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id),
Pad(axis=0, pad_val=tokenizer.pad_token_type_id),
Stack(dtype="int64"),
Stack(dtype="int64")
): fn(samples)
train_batch_sampler = paddle.io.BatchSampler(train_ds, batch_size=batch_size, shuffle=True)
dev_batch_sampler = paddle.io.BatchSampler(dev_ds, batch_size=batch_size, shuffle=False)
test_batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=batch_size, shuffle=False)
train_loader = paddle.io.DataLoader(train_ds, batch_sampler=train_batch_sampler, collate_fn=batchify_fn)
dev_loader = paddle.io.DataLoader(dev_ds, batch_sampler=dev_batch_sampler, collate_fn=batchify_fn)
test_loader = paddle.io.DataLoader(test_ds, batch_sampler=test_batch_sampler, collate_fn=batchify_fn)3.2.2模型构建
本案例中,我们将基于SKEP模型实现图1所展示的评论观点抽取功能。具体来讲,我们将处理好的文本数据输入SKEP模型中,SKEP将会对文本的每个token进行编码,产生对应向量序列。我们使用CLS位置对应的输出向量进行情感分类。相应代码如下。
class SkepForSequenceClassification(paddle.nn.Layer):
def __init__(self, skep, num_classes=2, dropout=None):
super(SkepForSequenceClassification, self).__init__()
self.num_classes = num_classes
self.skep = skep
self.dropout = paddle.nn.Dropout(dropout if dropout is not None else self.skep.config["hidden_dropout_prob"])
self.classifier = paddle.nn.Linear(self.skep.config["hidden_size"], num_classes)
def forward(self, input_ids, token_type_ids=None, position_ids=None, attention_mask=None):
_, pooled_output = self.skep(input_ids, token_type_ids=token_type_ids, position_ids=position_ids, attention_mask=attention_mask)
pooled_output = self.dropout(pooled_output)
logits = self.classifier(pooled_output)
return logits3.2.3 训练配置
接下来,定义情感分析模型训练时的环境,包括:配置训练参数、配置模型参数,定义模型的实例化对象,指定模型训练迭代的优化算法等,相关代码如下。
# model hyperparameter setting
num_epoch = 20
learning_rate = 3e-5
weight_decay = 0.01
warmup_proportion = 0.1
max_grad_norm = 1.0
log_step = 20
eval_step = 100
seed = 1000
checkpoint = "./checkpoint/"
set_seed(seed)
use_gpu = True if paddle.get_device().startswith("gpu") else False
if use_gpu:
paddle.set_device("gpu:0")
if not os.path.exists(checkpoint):
os.mkdir(checkpoint)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
num_training_steps = len(train_loader) * num_epoch
lr_scheduler = LinearDecayWithWarmup(learning_rate=learning_rate, total_steps=num_training_steps, warmup=warmup_proportion)
decay_params = [p.name for n, p in model.named_parameters() if not any(nd in n for nd in ["bias", "norm"])]
grad_clip = paddle.nn.ClipGradByGlobalNorm(max_grad_norm)
optimizer = paddle.optimizer.AdamW(learning_rate=lr_scheduler, parameters=model.parameters(), weight_decay=weight_decay, apply_decay_param_fun=lambda x: x in decay_params, grad_clip=grad_clip)
metric = AccuracyAndF1()3.2.4 模型训练与测试
本节我们将定义一个train函数和evaluate函数,其将分别进行训练和评估模型。在训练过程中,每隔log_steps步打印一次日志,每隔eval_steps步进行评估一次模型,并始终保存验证效果最好的模型。相关代码如下:
def evaluate(model, data_loader, metric):
model.eval()
metric.reset()
for batch_data in data_loader:
input_ids, token_type_ids, _, labels = batch_data
logits = model(input_ids, token_type_ids=token_type_ids)
correct = metric.compute(logits, labels)
metric.update(correct)
accuracy, precision, recall, f1, _ = metric.accumulate()
return accuracy, precision, recall, f1
def train():
# start to train model
global_step, best_f1 = 1, 0.
model.train()
for epoch in range(1, num_epoch+1):
for batch_data in train_loader():
input_ids, token_type_ids, _, labels = batch_data
# logits: batch_size, seql_len, num_tags
logits = model(input_ids, token_type_ids=token_type_ids)
loss = F.cross_entropy(logits, labels)
loss.backward()
lr_scheduler.step()
optimizer.step()
optimizer.clear_grad()
if global_step > 0 and global_step % log_step == 0:
print(f"epoch: {epoch} - global_step: {global_step}/{num_training_steps} - loss:{loss.numpy().item():.6f}")
if (global_step > 0 and global_step % eval_step == 0) or global_step == num_training_steps:
accuracy, precision, recall, f1 = evaluate(model, dev_loader, metric)
model.train()
if f1 > best_f1:
print(f"best F1 performence has been updated: {best_f1:.5f} --> {f1:.5f}")
best_f1 = f1
paddle.save(model.state_dict(), f"{checkpoint}/best_cls.pdparams")
print(f'evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')
global_step += 1
paddle.save(model.state_dict(), f"{checkpoint}/final_cls.pdparams")
train()接下来,我们将加载训练过程中评估效果最好的模型,并使用测试集进行测试。相关代码如下。
# load model
model_path = "./checkpoint/best_cls.pdparams"
loaded_state_dict = paddle.load(model_path)
skep = SkepModel.from_pretrained(model_name)
model = SkepForSequenceClassification(skep, num_classes=len(label2id))
model.load_dict(loaded_state_dict)accuracy, precision, recall, f1 = evaluate(model, test_loader, metric)
print(f'evalution result: accuracy:{accuracy:.5f} precision: {precision:.5f}, recall: {recall:.5f}, F1: {f1:.5f}')3.3 全流程模型推理
paddlepaddle也公开了训练好的模型参数,可以直接下载进行推理
# 下载评论观点抽取模型
!wget https://bj.bcebos.com/paddlenlp/models/best_ext.pdparams
# 下载属性级情感分类模型
!wget https://bj.bcebos.com/paddlenlp/models/best_cls.pdparamslabel_ext_path = "./data/data121190/label_ext.dict"
label_cls_path = "./data/data121242/label_cls.dict"
ext_model_path = "./best_ext.pdparams"
cls_model_path = "./best_cls.pdparams"
# load dict
model_name = "skep_ernie_1.0_large_ch"
ext_label2id, ext_id2label = data_ext.load_dict(label_ext_path)
cls_label2id, cls_id2label = data_cls.load_dict(label_cls_path)
tokenizer = SkepTokenizer.from_pretrained(model_name)
print("label dict loaded.")
# load ext model
ext_state_dict = paddle.load(ext_model_path)
ext_skep = SkepModel.from_pretrained(model_name)
ext_model = SkepForTokenClassification(ext_skep, num_classes=len(ext_label2id))
ext_model.load_dict(ext_state_dict)
print("extraction model loaded.")
# load cls model
cls_state_dict = paddle.load(cls_model_path)
cls_skep = SkepModel.from_pretrained(model_name)
cls_model = SkepForSequenceClassification(cls_skep, num_classes=len(cls_label2id))
cls_model.load_dict(cls_state_dict)
print("classification model loaded.")from tqdm import tqdm
import pandas as pd
tqdm.pandas()
Hotel_reviews1 = pd.read_excel(
'./data/2018-2019茂名(含自媒体).xlsx', sheet_name=0) # 酒店评论
Scenic_reviews1 = pd.read_excel(
'./data/2018-2019茂名(含自媒体).xlsx', sheet_name=1) # 景区评论
Travel_tips1 = pd.read_excel(
'./data/2018-2019茂名(含自媒体).xlsx', sheet_name=2) # 游记攻略
Dining_reviews1 = pd.read_excel(
'./data/2018-2019茂名(含自媒体).xlsx', sheet_name=3) # 餐饮评论
Wechat_article1 = pd.read_excel(
'./data/2018-2019茂名(含自媒体).xlsx', sheet_name=4) # 微信公众号文章
Hotel_reviews2 = pd.read_excel(
'./data/2020-2021茂名(含自媒体).xlsx', sheet_name=0) # 酒店评论
Scenic_reviews2 = pd.read_excel(
'./data/2020-2021茂名(含自媒体).xlsx', sheet_name=1) # 景区评论
Travel_tips2 = pd.read_excel(
'./data/2020-2021茂名(含自媒体).xlsx', sheet_name=2) # 游记攻略
Dining_reviews2 = pd.read_excel(
'./data/2020-2021茂名(含自媒体).xlsx', sheet_name=3) # 餐饮评论
Wechat_article2 = pd.read_excel(
'./data/2020-2021茂名(含自媒体).xlsx', sheet_name=4) # 微信公众号文章
Hotel_reviews = pd.concat([Hotel_reviews1, Hotel_reviews2],axis=0) # 酒店评论
Scenic_reviews = pd.concat([Scenic_reviews1, Scenic_reviews2], axis=0) # 景区评论
Travel_tips = pd.concat([Travel_tips1, Travel_tips2], axis=0) # 游记攻略
Dining_reviews = pd.concat([Dining_reviews1, Dining_reviews2], axis=0) # 餐饮评论
Wechat_article = pd.concat([Wechat_article1, Wechat_article2], axis=0) # 微信公众号文章import pandas as pdWechat_article = pd.read_csv('Wechat_article_product.csv',index_col=0).astype(str) # 微信公众号文章
Travel_tips = pd.read_csv('Travel_tips_product.csv',index_col=0).astype(str) # 游记攻略Wechat_article.head()def addstr(s):
return '游记ID-'+str(s)
Travel_tips['语料ID'] = Travel_tips['游记ID'].apply(addstr)
# Travel_tips['文本'] = Travel_tips['评论内容'] + '\n'+Dining_reviews['标题']
Travel_tips['产品名称'] = Travel_tips['mmr产品3']
Travel_tips['年份'] = pd.to_datetime(Travel_tips['发布时间']).dt.yeardef addstr(s):
return '文章ID-'+str(s)
Wechat_article['语料ID'] = Wechat_article['文章ID'].apply(addstr)
# Wechat_article['文本'] = Wechat_article['评论内容'] + '\n'+Dining_reviews['标题']
Wechat_article['产品名称'] = Wechat_article['mmr产品3']
Wechat_article['年份'] = pd.to_datetime(Wechat_article['发布时间']).dt.yearTravel_tips.head()Scenic_reviews.head(10)def addstr(s):
return '景区评论-'+str(s)
Scenic_reviews['语料ID'] = Scenic_reviews['景区评论ID'].apply(addstr)
Scenic_reviews['文本'] = Scenic_reviews['评论内容']
Scenic_reviews['产品名称'] = Scenic_reviews['景区名称']
Scenic_reviews['年份'] = pd.to_datetime(Scenic_reviews['评论日期']).dt.year
Scenic_reviews.head(10)def addstr(s):
return '酒店评论-'+str(s)
Hotel_reviews['语料ID'] = Hotel_reviews['酒店评论ID'].apply(addstr)
Hotel_reviews['文本'] = Hotel_reviews['评论内容']
Hotel_reviews['产品名称'] = Hotel_reviews['酒店名称']
Hotel_reviews['年份'] = pd.to_datetime(Hotel_reviews['评论日期']).dt.year
Hotel_reviews.head(10)Dining_reviews.head(10)def addstr(s):
return '餐饮评论-'+str(s)
Dining_reviews['语料ID'] = Dining_reviews['餐饮评论ID'].apply(addstr)
Dining_reviews['文本'] = Dining_reviews['评论内容'] + '\n'+Dining_reviews['标题']
Dining_reviews['产品名称'] = Dining_reviews['餐饮名称']
Dining_reviews['年份'] = pd.to_datetime(Dining_reviews['评论日期']).dt.year
Dining_reviews.head(10)# Scenic_reviews.index = range(len(Scenic_reviews))
Hotel_reviews.index = range(len(Hotel_reviews))
Dining_reviews.index = range(len(Dining_reviews))Scenic_reviews.head(10)import re
Scenic_reviews['文本']=Scenic_reviews['文本'].apply(lambda x:''.join(filter(lambda ch: ch not in ' \t◆#%', x)))
Scenic_reviews['文本']= Scenic_reviews['文本'].apply(lambda x: re.sub('&', ' ', x))
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub(' ', ' ', x))
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub('>', ' ', x))
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))
strinfo = re.compile('······')
Scenic_reviews['文本'] = Scenic_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))import re
Hotel_reviews['文本']=Hotel_reviews['文本'].apply(lambda x:''.join(filter(lambda ch: ch not in ' \t◆#%', x)))
Hotel_reviews['文本']= Hotel_reviews['文本'].apply(lambda x: re.sub('&', ' ', x))
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub(' ', ' ', x))
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub('>', ' ', x))
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))
strinfo = re.compile('······')
Hotel_reviews['文本'] = Hotel_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))import re
Dining_reviews['文本']=Dining_reviews['文本'].apply(lambda x:''.join(filter(lambda ch: ch not in ' \t◆#%', x)))
Dining_reviews['文本']= Dining_reviews['文本'].apply(lambda x: re.sub('&', ' ', x))
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub('"', ' ', x))
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub(' ', ' ', x))
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub('>', ' ', x))
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))
strinfo = re.compile('······')
Dining_reviews['文本'] = Dining_reviews['文本'].apply(lambda x: re.sub('<', ' ', x))import re
Travel_tips['正文']=Travel_tips['正文'].apply(lambda x:''.join(filter(lambda ch: ch not in ' \t◆#%', x)))
Travel_tips['正文']= Travel_tips['正文'].apply(lambda x: re.sub('&', ' ', x))
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub('"', ' ', x))
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub('"', ' ', x))
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub(' ', ' ', x))
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub('>', ' ', x))
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub('<', ' ', x))
strinfo = re.compile('······')
Travel_tips['正文'] = Travel_tips['正文'].apply(lambda x: re.sub('<', ' ', x))import re
Wechat_article['正文']=Wechat_article['正文'].apply(lambda x:''.join(filter(lambda ch: ch not in ' \t◆#%', x)))
Wechat_article['正文']= Wechat_article['正文'].apply(lambda x: re.sub('&', ' ', x))
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub('"', ' ', x))
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub('"', ' ', x))
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub(' ', ' ', x))
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub('>', ' ', x))
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub('<', ' ', x))
strinfo = re.compile('······')
Wechat_article['正文'] = Wechat_article['正文'].apply(lambda x: re.sub('<', ' ', x))!pip install zhconv# 繁体转中文
from zhconv import convert
for index,line in enumerate(Scenic_reviews['文本']):
# print(line)
lis1=[]
lis1=convert(str(line),'zh-cn')
Scenic_reviews.loc[index,'文本']=str(lis1)
# break# 繁体转中文
from zhconv import convert
for index,line in enumerate(Hotel_reviews['文本']):
# print(line)
lis1=[]
lis1=convert(str(line),'zh-cn')
Hotel_reviews.loc[index,'文本']=str(lis1)
# break# 繁体转中文
from zhconv import convert
for index,line in enumerate(Dining_reviews['文本']):
# print(line)
lis1=[]
lis1=convert(str(line),'zh-cn')
Dining_reviews.loc[index,'文本']=str(lis1)
# break# 繁体转中文
from zhconv import convert
for index,line in enumerate(Wechat_article['正文']):
# print(line)
lis1=[]
lis1=convert(str(line),'zh-cn')
Wechat_article.loc[index,'正文']=str(lis1)
# break# 繁体转中文
from zhconv import convert
for index,line in enumerate(Travel_tips['正文']):
# print(line)
lis1=[]
lis1=convert(str(line),'zh-cn')
Travel_tips.loc[index,'正文']=str(lis1)
# breakDining_reviews.head(5)Hotel_reviews.head(5)# !pip install zhconvdef predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=512):
ext_model.eval()
cls_model.eval()
# processing input text
encoded_inputs = tokenizer(list(input_text), is_split_into_words=True, max_seq_len=max_seq_len,)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
# extract aspect and opinion words
logits = ext_model(input_ids, token_type_ids=token_type_ids)
predictions = logits.argmax(axis=2).numpy()[0]
tag_seq = [ext_id2label[idx] for idx in predictions][1:-1]
aps = decoding(input_text, tag_seq)
# predict sentiment for aspect with cls_model
results = []
for ap in aps:
aspect = ap[0]
opinion_words = list(set(ap[1:]))
aspect_text = concate_aspect_and_opinion(input_text, aspect, opinion_words)
encoded_inputs = tokenizer(aspect_text, text_pair=input_text, max_seq_len=max_seq_len, return_length=True)
input_ids = paddle.to_tensor([encoded_inputs["input_ids"]])
token_type_ids = paddle.to_tensor([encoded_inputs["token_type_ids"]])
logits = cls_model(input_ids, token_type_ids=token_type_ids)
prediction = logits.argmax(axis=1).numpy()[0]
result = {"aspect": aspect, "opinions": opinion_words, "sentiment": cls_id2label[prediction]}
results.append(result)
# format_print(results)
# print(result)
return results
max_seq_len = 512
input_text = """10月1号全家自驾游去了中国第一滩,沙滩和海水都算挺干净的,停车场按次收费一次30元,停车场保安态度极差,不知他哪来的自信,他自我感觉比较优越,在沙滩旁边有冲淡水浴的店铺,冷水5元一位热水15元一位,但是很多人要排队,于是我们走远一点去沙滩入口图4这家,冷水3元一位,热水10元一位,我们两个小孩要了两个热水加一包洗发水共支付21元,店铺老板娘态度极其恶劣,只顾收钱,收了钱之后什么都不管,刚开始去到问价格,问了三四次才回答,小孩湿身上岸之后感觉比较冷,进去找不到热水间,出来找老板娘,她说我们没给钱,让我先给了,我说明明给过了她才慢吞吞的带我们进去马上又走了,结果热水用不了,我又要跑出去找她,她又慢吞吞的进来,我一个人帮两个小孩洗头冲凉,就算半小时都不为过,但帮我们冲了都还没有15分钟,有人在排队了,她们就开始赶人,后来我就两个小孩用一个花洒,浴间设施很简陋,没有门,只有一块遮不住的布,不分男女,小孩洗洗还可以,大人千万不能洗,我有一个小孩没有带衣服,我妈去车上拿衣服进去,后来我们4个人一起出来,那个老板娘还用乡下话嫌弃的说了一句:“哇,不用钱啊,那么多个人”我只说了句:两个大人帮两个小孩洗澡穿衣服,难免会身水身汗。在这里我想对这个老板娘说:这种鬼地方送给我都不会在这里冲的,生意不能这样做的,或者你在旅游区只想做一次性生意,但你这样子很快会倒闭。洗完澡去吃饭,才知道我们去的那家店铺里面都可以免费洗澡的,而且有单独的洗浴间有冷热水,餐厅出品也不错,服务态度也挺好,一天的不愉快烟消云散。"""
if len(input_text)>512:
input_text=input_text[0:510]
len(input_text)
a=predict(input_text, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
amax_seq_len = 512
for index,line in enumerate(Scenic_reviews['文本']):
res1=[]
res2=[]
res3=[]
if len(line)>510:
line=line[0:510]
lis=predict(line, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
# print(ress)
for item in lis:
for name,values in item.items():
res1.append(values.title())
res2.append(values.title())
res3.append(values.title())
values.title()
# res1.append(list(item.values())[0])
# res2.append(list(item.values())[1])
# res3.append(list(item.values())[2])
str1 = ",".join('%s' %a for a in res1)
str2 = ",".join('%s' %a for a in res2)
str3 = ",".join('%s' %a for a in res3)
Scenic_reviews.loc[index,"aspect"]=str1
Scenic_reviews.loc[index,"opinions"]=str2
Scenic_reviews.loc[index,"sentiment"]=str3四、计算产品热度
4.1 方面级情感极性预测及计算情感分数
import collections
max_seq_len = 512
for index,line in enumerate(Hotel_reviews['文本']):
aspsent=[]
res1=[]
res2=[]
res3=[]
score=[]
if len(line)>510:
line=line[0:510]
lis=predict(line, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
keys = ['aspect', 'opinions']
asp=['aspect']
opi=['opinions']
sent=['sentiment']
aspsent = [dict((k, d[k]) for k in keys) for d in lis]
res1=[d[k] for k in asp for d in lis]
res2=[d[k] for k in opi for d in lis]
res3=[d[k] for k in sent for d in lis]
# 统计情感得分
score=collections.Counter(res3)
# print("正向得分",m1["正向"],"负向得分",m1["负向"])
fin_score=score["正向"]-score["负向"]
str1 = ",".join('%s' %a for a in res1)
str2 = ",".join('%s' %a for a in res2)
str3 = ",".join('%s' %a for a in res3)
Hotel_reviews.loc[index,"aspect"]=str1
Hotel_reviews.loc[index,"opinions"]=str2
Hotel_reviews.loc[index,"sentiment"]=str3
Hotel_reviews.loc[index,"aspect&opinions"]=str(aspsent)
Hotel_reviews.loc[index,"情感分数"]=str(fin_score)import collections
max_seq_len = 512
for index,line in enumerate(Travel_tips['正文']):
aspsent=[]
res1=[]
res2=[]
res3=[]
score=[]
if len(line)>510:
line=line[0:510]
lis=predict(line, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
keys = ['aspect', 'opinions']
asp=['aspect']
opi=['opinions']
sent=['sentiment']
aspsent = [dict((k, d[k]) for k in keys) for d in lis]
res1=[d[k] for k in asp for d in lis]
res2=[d[k] for k in opi for d in lis]
res3=[d[k] for k in sent for d in lis]
# 统计情感得分
score=collections.Counter(res3)
# print("正向得分",m1["正向"],"负向得分",m1["负向"])
fin_score=score["正向"]-score["负向"]
str1 = ",".join('%s' %a for a in res1)
str2 = ",".join('%s' %a for a in res2)
str3 = ",".join('%s' %a for a in res3)
Travel_tips.loc[index,"aspect"]=str1
Travel_tips.loc[index,"opinions"]=str2
Travel_tips.loc[index,"sentiment"]=str3
Travel_tips.loc[index,"aspect&opinions"]=str(aspsent)
Travel_tips.loc[index,"情感分数"]=str(fin_score)import collections
max_seq_len = 512
for index,line in enumerate(Wechat_article['正文']):
aspsent=[]
res1=[]
res2=[]
res3=[]
score=[]
if len(line)>510:
line=line[0:510]
lis=predict(line, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
keys = ['aspect', 'opinions']
asp=['aspect']
opi=['opinions']
sent=['sentiment']
aspsent = [dict((k, d[k]) for k in keys) for d in lis]
res1=[d[k] for k in asp for d in lis]
res2=[d[k] for k in opi for d in lis]
res3=[d[k] for k in sent for d in lis]
# 统计情感得分
score=collections.Counter(res3)
# print("正向得分",m1["正向"],"负向得分",m1["负向"])
fin_score=score["正向"]-score["负向"]
str1 = ",".join('%s' %a for a in res1)
str2 = ",".join('%s' %a for a in res2)
str3 = ",".join('%s' %a for a in res3)
Wechat_article.loc[index,"aspect"]=str1
Wechat_article.loc[index,"opinions"]=str2
Wechat_article.loc[index,"sentiment"]=str3
Wechat_article.loc[index,"aspect&opinions"]=str(aspsent)
Wechat_article.loc[index,"情感分数"]=str(fin_score)import collections
max_seq_len = 512
for index,line in enumerate(Dining_reviews['文本']):
aspsent=[]
res1=[]
res2=[]
res3=[]
score=[]
if len(line)>510:
line=line[0:510]
lis=predict(line, ext_model, cls_model, tokenizer, ext_id2label, cls_id2label, max_seq_len=max_seq_len)
keys = ['aspect', 'opinions']
asp=['aspect']
opi=['opinions']
sent=['sentiment']
aspsent = [dict((k, d[k]) for k in keys) for d in lis]
res1=[d[k] for k in asp for d in lis]
res2=[d[k] for k in opi for d in lis]
res3=[d[k] for k in sent for d in lis]
# 统计情感得分
score=collections.Counter(res3)
# print("正向得分",m1["正向"],"负向得分",m1["负向"])
fin_score=score["正向"]-score["负向"]
str1 = ",".join('%s' %a for a in res1)
str2 = ",".join('%s' %a for a in res2)
str3 = ",".join('%s' %a for a in res3)
Dining_reviews.loc[index,"aspect"]=str1
Dining_reviews.loc[index,"opinions"]=str2
Dining_reviews.loc[index,"sentiment"]=str3
Dining_reviews.loc[index,"aspect&opinions"]=str(aspsent)
Dining_reviews.loc[index,"情感分数"]=str(fin_score)Hotel_reviews.to_excel("Hotel_reviews.xlsx")
Dining_reviews.to_excel("Dining_reviews.xlsx")Wechat_article.to_excel("Wechat_article.xlsx")
Travel_tips.to_excel("Travel_tips.xlsx")Scenic_reviews.to_excel("Scenic_reviews.xlsx")aa=eval(Scenic_reviews['aspect&opinions'][0])
for alien in aa:
print(alien)
print(type(alien))Scenic_reviews=Scenic_reviews.drop(["aspect&sentiment","sentiment","情感分数","aspect&opinions","aspect","opinions"],axis=1)
Scenic_reviews.head()aliens = []
for alien_number in range (0,5):
new_alien = {'color': 'green', 'points': 5, 'speed': 'slow'}
aliens.append(new_alien)
# print("The following languages have been mentioned:")
# rt=[]
# for language in favorite_languages.values():
# print(str(favorite_languages.values()))
# ",".join('%s' %a for a in favorite_languages.values())
# for members in aliens:
# print(members["color"], members["speed"])
# print(list(members.items())[0]+list(members.items())[1])
# print(members.values())
# print(members.keys())
# print("\tage: {}".format(members["age"]))
# print("\tcity: {}".format(members["city"]))
keys = ['color', 'speed']
se = ['points']
new_data = [dict((k, d[k]) for k in keys) for d in aliens]
res1 = [d[x] for x in se for d in aliens]
str1 = ",".join('%s' %a for a in res1)
# dicrs=dict(zip(favorite_languages,favorite_languages[1]))
# new_data
lrs=['正向','负向']
import collections
res1
m1=collections.Counter(lrs)
print(collections.Counter(res1))
print(collections.Counter(str1))
print(collections.Counter(lrs))
print("正向得分",m1["正向"],"负向得分",m1["负向"])
print(m1["正向"]-m1["负向"])4.2 统计产品情感热度得分
import collections
for index,line in enumerate(Scenic_reviews['sentiment']):
m1=[]
m1=collections.Counter(line)
# res1.append(m1[0])
# m1['正向']
# res2.append(list(item.values())[1])
# res3.append(list(item.values())[2])
# Scenic_reviews.loc[index,"情感得分"]=str(int(m1['正向'])-int(m1['负向']))
print("正向得分",m1['正'],"负向得分",m1['负'],line)
breakcolors = ['red', 'blue', 'red', 'green', 'blue', 'blue']
c = collections.Counter(colors)
cScenic_reviews.to_excel("s.xlsx")# max_seq_len = 512
# b=[]
# ress=[]
# df=pd.DataFrame()
# for item in a:
# # for k,v in item.items():
# ress.append(list(item.values())[2])
# print(ress)
# # print(k,v)
# # print(v[:])
# # ','.join(k["aspect"])
# # abc=","+v[:]
# # k["aspect"]
# # print(k)
# df.loc[1,"as"]=str(ress)
# df.head()五. 致谢
[1] H. Tian et al., “SKEP: Sentiment Knowledge Enhanced Pre-training for Sentiment Analysis,” arXiv:2005.05635 [cs], May 2020, Accessed: Nov. 11, 2021.
[2] 小余同学的博客

 ]
]